GAWK 文字列をバイト単位(表示長さ)で数える
文字列の表示長さを取得するために Shift_JIS/UTF-8
一つのスクリプトの中で、文字列の文字数(キャラクタ単位)と表示の長さ(半角単位)両方を取得できると、日本語テキストを扱う上では何かと便利です。文字数は length() で取得できますので、表示の長さを取得する方法を提示します。
仕組みは単純です。半角として数えるべき文字の集合を、辞書としてBEGIN先頭で初期化し、
blength(str)という関数を用いて、str を一文字ずつこの辞書と照合して、半角を 1 、それ以外を 2 としてカウント(抽象概念:疑似バイト)し、合計結果を返します。半角辞書にはASCIIに規定される 128個の文字・制御文字が含まれますので、エスケープシーケンスはもちろん、しばしば使用されるSUBSEP( 0x1C )もキチンと認識します。 半角カナにも対応します。str 中に現れる改行文字( \n )は、Windows ではCRLF( 0D0A )ですが、1 半角文字 ( 0A ) としてカウントします。(2バイト換算したい場合は別途集計する)
処理時間はだいたいノーマル(マルチバイトモード) length() の 8 倍~ くらいかかるようです(筆者の環境/重さのテスト参照)。
※ UTF-8 / MSYS2 環境(スクリプトも UTF-8)でも使用できますが、表示長さのみを求めることができます。文字コード(ASCII以外)及びバイト数は合致しません。文字コードが必要であれば半角カナの文字コードを書き換えてください。バイトは算出できません。
※UTF-8において、特殊な半角文字(発声記号やラテン文字拡張等)が必要な場合は追加で辞書に登録してください。
awk_blength_basic.awk
1 : #. awk_blength_basic.awk;blength()の検証
2 : #. BEGIN;
3 : BEGIN {
4 : _asc_init();
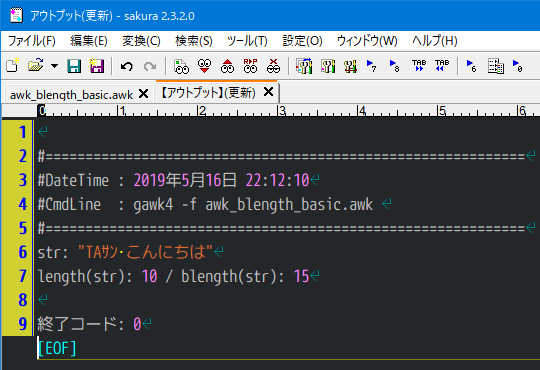
5 : str = "TAサン" SUBSEP "こんにちは";
6 : print "str: \"" str "\"";
7 : print "length(str): " length(str) " / blength(str): " blength(str);
8 : }
9 : #. _asc_init();ASCII+半角カナ辞書(Shift_JIS)
10 : function _asc_init( i, hk, ar, qt) {
11 : for (i = 0; i < 128; i++) _asc[sprintf("%c", i)] = i;
12 : hk = "。「」、・ヲァィゥェォャュョッーアイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワン゙゚";
13 : qt = split(hk, ar, "");
14 : for (i = 1; i <= qt; i++) _asc[ar[i]] = 160 + i; #Shift_JIS
15 : _SCLP = " "; #マルチバイト文字の断片を表す文字
16 : }
辞書を作ります。
GAWK の配列が連想配列であること、ASCIIに重複するアイテムがないことを利用して、配列の添字(インデックス)にASCII文字(制御文字含む)そのものを使用します。半角カナも同様です。
※ここで言う「そのもの」とは、逆説的にソースの文字セットに依存するということで、UTF-8/Shift_JIS、その他GAWKで使用できるどんな文字セットであれ、現物が必要であるということです。
(_ascの値はShift_JIS※ord()等で取り出さない限り使用しない)
これにより、この辞書 _asc におけるある文字の存在確認、すなわち、
if (ch in _asc)
とすることができるようになります。半角文字合計 191 個のインデックスを走査しますが、この判定は実態がハッシュテーブルであるため驚異的に高速です。
この関数は、BEGIN先頭で1度だけ実行され、プログラム終了まで辞書配列(グローバル)を保持します。なので他の関数(blength/bsubstr/bsformat 等)から何万回でも参照可能となります。実際、後述のテストでは100万回参照しています。
17 : #. blength();文字列長さ疑似バイトを返す(辞書_asc)
18 : function blength(str, i, ch, lenb) {
19 : lenb = 0;
20 : while (ch = substr(str, ++i, 1))
21 : (ch in _asc) ? lenb += 1 : lenb += 2;
22 : return lenb;
23 : }
文字列の表示長さ(疑似バイト)を返します。
Shift_JISをお使いの方は単純にバイトだと解釈してください。UTF-8をお使いの方は半角を1単位とする文字列全体の表示長と解釈してください。UTF-8のバイトは返せません。
19行 わざわざ初期化するのは、str が空文字の場合 lenb が空文字を返してしまうからです。
20行 while は ch == "" (str が空文字または str 終端の次を取り出そうとする)で停止します。
21行 上述の辞書配列 _asc に存在しない文字は、すべて表示長さ 2 の文字(日本語限定の場合)です。
文字列を先頭から1文字づつ取り出し、辞書と照合し、その表示長さを集計して値を返します。
この仕様であるため、この関数は負荷が大きく重くなります。
実行結果
 UTF-8/MSYS2/GAWK5.0
UTF-8/MSYS2/GAWK5.0
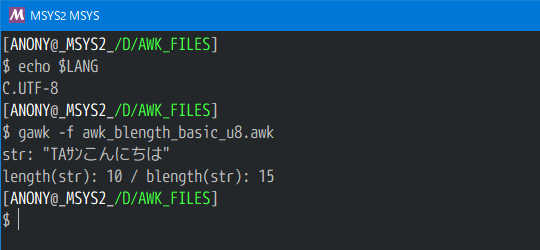
※MSYS2の出力(コンソール)では SUBSEP の表示長は「0」なので注意
どれくらい重いのかテストしてみます。
無理やりな例ですが、下記のファイルサイズ(Shift_JISテキスト)を求めるスクリプトで、
awk_blength_FileSize.awk
1 : @load "time";
2 : BEGIN {
3 : _asc_init();
4 : _time = gettimeofday();
5 : }
6 :
7 : {
8 : _byte += blength($0);
9 : }
10 :
11 : END {
12 : _time = gettimeofday() - _time;
13 : print "FileSize = " _byte + FNR * 2 "byte";
14 : printf("elapsed time = %d(msec)", _time * 1000);
15 : }
「1行あたり全半角混成100文字(組成はrandom) / 10,000行 / 1,733,054 byte」のファイルを
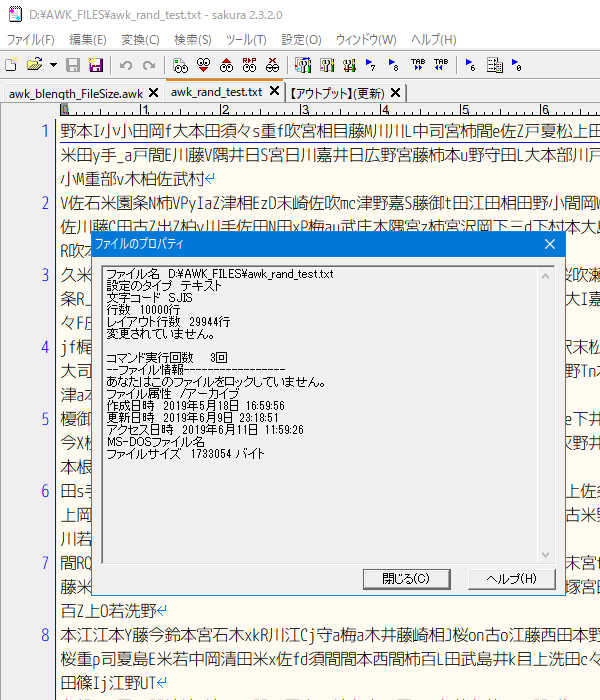
処理すると
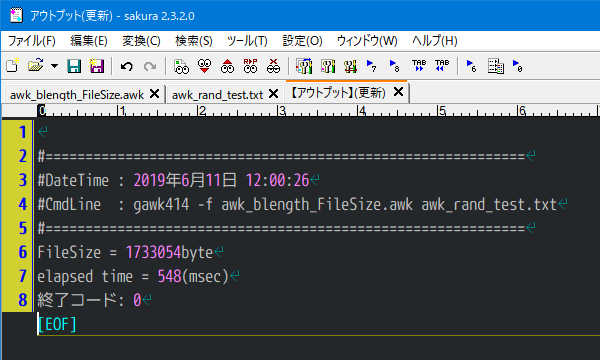
計測結果 548ミリ秒 (0.548秒) と、100文字 1万行 (約1800字/ミリ秒)くらいでは重すぎて使えないほどではありません。この処理速度を目安に使いどころを考えるというのが、賢い利用法だと思います。
(このロジックの応用:表示長さ単位の文字列切り出し / 文字列整形)
UTF-8 の環境ではこの例はまったく無意味ですが、文字列の表示長さに関しては、おそらくこの方法でしか取得できません。もっとも、正規表現を使うことも考えられますが、はっきり言って、この用途には不向きです。同様の計測で 1386ミリ秒でした。興味のある方は、実験して確かめてみてください。
1 : #. rblength();blength 正規表現を使用した例
2 : function rblength(str, i, ch, lenb) {
3 : lenb = 0;
4 : while (ch = substr(str, ++i, 1))
5 : (ch ~ /[\x00-\x7F。「」、・ヲァィゥェォャュョッーアイウエオカキクケコサシスセソ\
6 : タチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワン゙゚]/) ? lenb += 1 : lenb += 2;
7 : return lenb;
8 : }さて、Shift_JIS UTF-8ともに表示の長さを取得できるということは、日本語文字列操作について、ほぼ不可能なことはなくなったと考えてよいでしょう。下記にその一端を付録として掲載していますので、よろしければご覧ください。
蛇足
blength() は、ローカル変数を使用しないようにすると、1割弱速くなります。しかし、使う頻度が多い場合は、ローカルとした方が保守性はいいかもしれません。
文字セットが「Shift_JIS」でエクステンションが使える環境であれば、別ページの"win_sjis.dll" / lengthb() の使用をお勧めします。こちらの仕様は数えないので、負荷はほぼありません。上記のファイルサイズテストを 32ミリ秒 で処理します。
ちなみに ノーマルモード length() で上記のキャラクタ数を調べると 処理時間は 97ミリ秒 でした。$0 を変数に1万回格納するだけのプログラムで 30ミリ秒かかりますので、予想される length() と blength() の処理速度の差はおよそ 8倍くらいとみています。
また、このページの趣旨である「1 スクリプトでキャラクタ数と表示長さを両方使用できる」に反しますが、 GAWK をバイトモード(-b オプション)にして上記を length() で処理すると 32ミリ秒でした。
(処理時間計測値は5回平均。筆者のPCスペックはこちら)
APPENDIX
_asc_init() を使用する blength() の応用です。
bindex() バイト(表示長さ)指向で文字列を検索する UTF-8/Shift_JIS
GAWK4 for win32 バイトモード動作(Shift_JIS)の index(string, find) と同様の結果を得られます。
BEGIN 先頭に _asc_init() が必要です。
1 : #. bindex();文字列から文字列を検索し位置を疑似バイトで返す
2 : # 戻り値:検索文字列の先頭位置(疑似バイト)
3 : # str: 対象文字列
4 : # find: 検索文字列
5 : function bindex(str, find, ch, i, lenb, mbc) {
6 : if (str = substr(str, 1, index(str, find))) {
7 : (substr(find, 1, 1) in _asc) ? mbc = 0 : mbc = 1;
8 : while (ch = substr(str, ++i, 1))
9 : (ch in _asc) ? lenb += 1 : lenb += 2;
10 : return (mbc) ? lenb - 1 : lenb;
11 : }
12 : else return 0;
13 : }
テストコード
1 : BEGIN {
2 : _asc_init();
3 : scale = "12345678901234567890123456789012"
4 : str = "123肆伍陸789拾123肆伍陸789弐拾12";
5 :
6 : print scale "\n" str "\nsearch \"弐拾\"";
7 : print " index result = " index(str, "弐拾");
8 : print "bindex result = " bindex(str, "弐拾");
9 :
10 : print "\nsearch \"789\"";
11 : print " index result = " index(str, "789");
12 : print "bindex result = " bindex(str, "789");
13 : }
実行結果
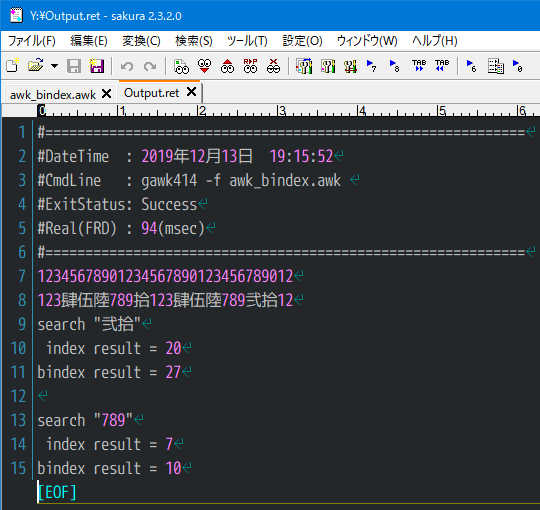 UTF-8/MSYS2/GAWK5.0
UTF-8/MSYS2/GAWK5.0
UTF-8 環境では -b オプションは、使途不明な値を返します。
この関数は、下記 bsubstr() のために使うことになると思います。
bsubstr() バイト(表示長さ)指向で文字を切り出す UTF-8/Shift_JIS
GAWK4 for win32 バイトモード動作(Shift_JIS)の substr(string, bytes1, bytes2) と同様の結果を得られ、文字化けを回避します。
※文字化け原因のマルチバイト文字断片(仮想)は _asc_init() の _SCLP に置き換えられます。
※第三引数は省略できます(substr()同様)。
BEGIN 先頭に _asc_init() が必要です。
1 : #. bsubstr();文字列を指定表示長さ(バイト)で切り出す(Shift_JIS/UTF-8)
2 : # str:対象文字列 bytes1:開始位置(表示長さ単位) bytes2:表示長さ
3 : # 切り出しに伴うマルチバイト文字の断片は_asc_init()の_SCLPで表される
4 : function bsubstr(str, bytes1, bytes2, lenb,\
5 : b2f, ch, i, si, mbc, head) {
6 : if (bytes2 == "") { bytes2 = 1; b2f = 1; } # substr()
7 : if (bytes2 < 1) return ""; # substr()
8 : if (bytes1 < 1) bytes1 = 1; # substr()
9 : #切り出し開始位置(siとheadを求める)
10 : if (bytes1 == 1) si = 1; # head=""
11 : else {
12 : while (ch = substr(str, ++i, 1)) {
13 : if (ch in _asc) { mbc = 0; lenb += 1; }
14 : else { mbc = 1; lenb += 2; }
15 : if (lenb < bytes1) ;
16 : else if (lenb == bytes1) {
17 : if (!mbc) si = i; #SB文字 head=""
18 : else { si = i + 1; head = _SCLP; } #MB文字第2バイト(ゴミ)
19 : break;
20 : } else { si = i; break; } #MB文字第1バイト head=""
21 : }
22 : if (!si) return ""; # str="" or bytes1>lenb
23 : }
24 : if (b2f) return head substr(str, si);
25 : #切り出し開始位置がゴミ: 1バイト減らす →zero ゴミだけ返す
26 : if (head) { bytes2 -= 1; if (!bytes2) return head; }
27 : #切り出し
28 : lenb = 0;
29 : i = si - 1; #次文で前置インクリメント(i=siで開始)
30 : while (ch = substr(str, ++i, 1)) {
31 : (ch in _asc) ? lenb += 1 : lenb += 2;
32 : if (lenb < bytes2) ;
33 : else if (lenb == bytes2)
34 : return head substr(str, si, i - si + 1); #ゴミなし
35 : else
36 : return head substr(str, si, i - si) _SCLP; #MB文字第1バイト(ゴミ)
37 : }
38 : return head substr(str, si); # bytes2>lenb (残文)
39 : }
テストコード
1 : #. BEGIN;bsubstr()を検証する
2 : BEGIN {
3 : _asc_init();
4 : str = "今日はBランチで!";
5 :
6 : print "\n123456789A123456\n" str "<endl\n";
7 : for (i = 0; i < 18; i++)
8 : printf("bsubstr(str, %2d, %2d) :%s<endl\n",\
9 : i, i, bsubstr(str, i, i));
10 : }
実行結果
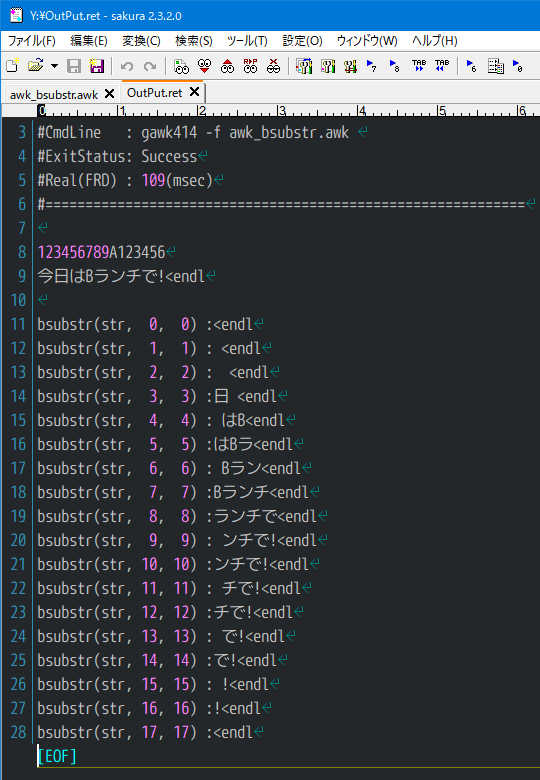 UTF-8/MSYS2/GAWK5.0
UTF-8/MSYS2/GAWK5.0
参考 -b オプション バイトモード substr() にて実行
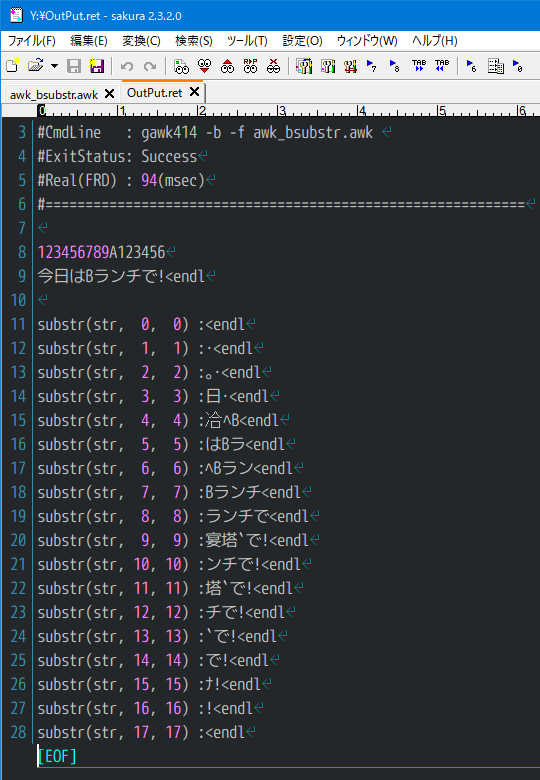
文字化けしてしまいます。UTF-8環境ではさらに酷いことになってしまいます。
どうでしょう、この関数の重要性がご理解いただけましたでしょうか。
切り出す位置と切り出す量で速度はかなり変わります。先頭から近くて短いと速くなります。合計すると、ちょうど文字列全体が 1ループセットですから、ループを途中で抜けると速いに決まってますよね。
前述の 100文字/1万行 のテキストにて、表示長さ 5 の位置から幅表示長さ 20 の文字列を取り出すのにかかる処理時間は 223ミリ秒、表示長さ 100 の位置から幅表示長さ 100 (ループをすべて回す)では、658ミリ秒でした。
bsformat() バイト(表示長さ)指向で文字列を整形する UTF-8/Shift_JIS
GAWK4 for win32 バイトモード動作(Shift_JIS)の sprintf("%*.*s", fw, prec, string) と同様の結果が得られ、文字化けを回避します。
※文字化け原因のマルチバイト文字断片(仮想)は _asc_init() の _SCLP に置き換えられます。
※引数は省略できません(prec を無効にしたいときは負の整数)。
BEGIN 先頭に _asc_init() が必要です。
1 : #. bsformat();Shift_JIS/UTF-8 文字列整形
2 : # fw:最小列幅 prec:最大出力 str:対象文字列
3 : # fw>0 右寄せ fw<0 左寄せ fw=0 fw無効
4 : # prec<0 prec無効 prec=0 文字列無
5 : # precに伴うマルチバイト文字の断片は_asc_init()の_SCLPで表される
6 : function bsformat(fw, prec, str, ch, \
7 : i, lenb, flg, ret, absfw) {
8 : (prec < 0) ? flg = 1 : flg = 0; #prec無効
9 : lenb = 0;
10 : while (ch = substr(str, ++i, 1)) {
11 : (ch in _asc) ? lenb += 1 : lenb += 2;
12 : if (flg) continue;
13 : if (lenb < prec) ;
14 : else if (lenb == prec) { ret = substr(str, 1, i); break; }
15 : else { ret = substr(str, 1, i - 1) _SCLP; break; } #ゴミ
16 : } #lenb:str表示長さ
17 : if (prec > 0 && prec <= lenb) ; #whileでret格納済み
18 : else if (prec) { prec = lenb; ret = str; } #上書き prec<0 prec>lenb
19 : else ret = ""; #上書き prec=0
20 :
21 : (fw < 0) ? absfw = -fw : absfw = fw;
22 : if (!absfw || absfw <= prec) return ret;
23 : else if (fw > 0) return sprintf("%*s", absfw - prec, "") ret; #右寄せ
24 : else return ret sprintf("%*s", absfw - prec, ""); #左寄せ
25 : }
テストコード
1 : #. bsformat();検証
2 : BEGIN {
3 : _asc_init();
4 : counter = "123456789A123456789A123456789A"
5 :
6 : book[1] = "プログラミング言語AWK";
7 : book[2] = "正規表現辞典";
8 : book[3] = "AWKを256倍使うための本";
9 : book[4] = "シェル芸に効く!AWK処方箋";
10 : book[5] = "sed & awkプログラミング";
11 : book[6] = "AWK実践入門";
12 :
13 : print "「右寄せ、列幅30、最大出力数無効」\n" counter;
14 : for (i in book) print bsformat(30, -1, book[i]);
15 : print "\n「左寄せ、列幅30、最大10(半角文字)」\n" counter;
16 : for (i in book) print bsformat(-30, 10, book[i]);
17 : }
実行結果
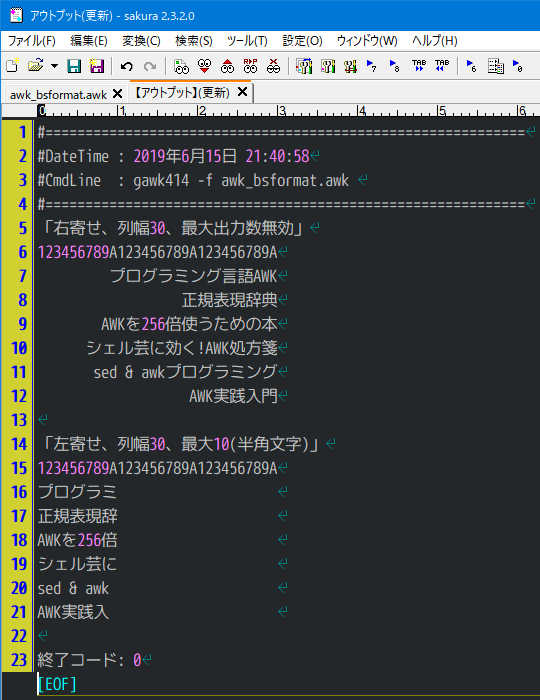 /UTF-8/MSYS2/GAWK5.0
/UTF-8/MSYS2/GAWK5.0
 改行位置を明確にするため行末に < を付加している
改行位置を明確にするため行末に < を付加している
以下同文です。
(UTF-8環境で sprintf()による日本語整形はそもそも無理がある)
蛇足ですが、1列の全半角混在の文字数不定データを、横並びに4列表示したいとき、以下のように書いて出力することができます。
1 : BEGIN {
2 : _asc_init();
3 : COL = 4; #表示列数
4 : DGT = 3; #行番号桁数
5 : OUT = 80; #出力桁数
6 : _tmp = (OUT - 1) - COL * (DGT + 2);
7 : PRC = (_tmp - _tmp % COL) / COL; #最大出力文字数
8 : }
9 :
10 : {
11 : _str = _str sprintf("%*s:", DGT, NR) bsformat(-(PRC + 1), PRC, $0);
12 : if (!(NR % COL)) { print _str; _str = ""; }
13 : }
14 :
15 : END {
16 : if (_str) print _str;
17 : }
 データはランダム(文字化けしているわけではない)
データはランダム(文字化けしているわけではない)
索引のように縦に並んだ複数列表示は getline()で先読みし、配列にしてしまう方がいいでしょう。以下のようになります。
1 : BEGIN {
2 : _asc_init();
3 : COL = 4; #表示列数
4 : DGT = 3; #行番号桁数
5 : OUT = 80; #出力桁数
6 : tmp = (OUT - 1) - COL * (DGT + 2);
7 : PRC = (tmp - tmp % COL) / COL; #最大出力文字数
8 :
9 : while (getline < ARGV[1] > 0) lines[++i] = $0;
10 : close(ARGV[1]);
11 : last = i;
12 : if (last % COL) turn = (last - last % COL) / COL + 1;
13 : else turn = last / COL;
14 :
15 : for (i = 1; i <= turn; i++) {
16 : for (j = 0; j < COL; j++) {
17 : num = i + j * turn;
18 : if (num <= last) str = str sprintf("%*s:", DGT, num) \
19 : bsformat(-(PRC + 1), PRC, lines[num]);
20 : }
21 : print str;
22 : str = "";
23 : }
24 : }
前述のものと合わせて少しいじると表示優先の「column」(ツール)ができそうです。
textf() テキストを指定桁で簡易整形する UTF-8/Shift_JIS
見出しは関数ですが、これは汎用関数ではなく、実験的ツールです。
次のテキストを40桁(表示長さ 40)で整形します。例文は動作を見るため原文を多少加工してあります。
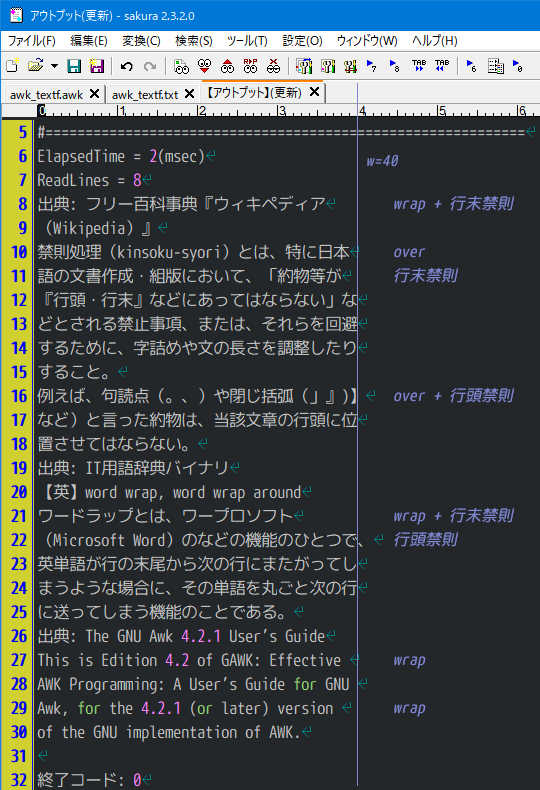
awk_textf.txt
出典: フリー百科事典『ウィキペディア(Wikipedia)』
禁則処理(kinsoku-syori)とは、特に日本語の文書作成・組版において、「約物等が『行頭・行末』などにあってはならない」などとされる禁止事項、または、それらを回避するために、字詰めや文の長さを調整したりすること。
例えば、句読点(。、)や閉じ括弧(」』)】など)と言った約物は、当該文章の行頭に位置させてはならない。
出典: IT用語辞典バイナリ
【英】word wrap, word wrap around
ワードラップとは、ワープロソフト(Microsoft Word)のなどの機能のひとつで、英単語が行の末尾から次の行にまたがってしまうような場合に、その単語を丸ごと次の行に送ってしまう機能のことである。
出典: The GNU Awk 4.2.1 User’s Guide
This is Edition 4.2 of GAWK: Effective AWK Programming: A User’s Guide for GNU Awk, for the 4.2.1 (or later) version of the GNU implementation of AWK.
awk_textf.awk
1 : #. test1 textf()
2 : @load "time";
3 : BEGIN {
4 : _time = gettimeofday();
5 : _textf_init();
6 : }
7 :
8 : {
9 : textf($0, 40);
10 : }
11 :
12 : END {
13 : _time = gettimeofday() - _time;
14 : printf("ElapsedTime = %d(msec)\n", _time * 1000);
15 : print "ReadLines = " FNR;
16 : print "MakeLines = " _TFCT;
17 : for (i = 1; i <= _TFCT; i++) print _TFAR[i];
18 : }
19 : #. _asc_init();ASCII+半角カナ辞書(Shift_JIS)
20 : function _asc_init( i, hk, ar, qt) {
21 : for (i = 0; i < 128; i++) _asc[sprintf("%c", i)] = i;
22 : hk = "。「」、・ヲァィゥェォャュョッーアイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワン゙゚";
23 : qt = split(hk, ar, "");
24 : for (i = 1; i <= qt; i++) _asc[ar[i]] = 160 + i; #Shift_JIS
25 : _SCLP = " "; #マルチバイト文字の断片を表す文字
26 : }
27 : #. _textf_init();textf()初期設定
28 : function _textf_init( i, ar, fbd, qt) {
29 : if (!("A" in _asc)) { delete _asc; _asc_init(); }
30 : for (i in _asc) _hfc[i]; #_asc[]をコピー
31 : _hfc["‘"] = 33125; #左引用符:0x8165
32 : _hfc["’"] = 33126; #右引用符:0x8166
33 : _hfc["“"] = 33127; #左二重引用符:0x8167
34 : _hfc["”"] = 33128; #右二重引用符:0x8168
35 :
36 : fbd = " ’”-=~.,:;!?}])";
37 : qt = split(fbd, ar, "");
38 : for (i = 1; i <= qt; i++) _fbd_wrap[ar[i]] = 1; #wrap 抑制文字種
39 : delete ar;
40 : fbd = "「『【({[({";
41 : qt = split(fbd, ar, "");
42 : for (i = 1; i <= qt; i++) _fbd_end[ar[i]] = 1; #行末禁則文字種
43 : delete ar;
44 : fbd = "。、」』】)}ー~・!?-=~.,:;!?}])";
45 : qt = split(fbd, ar, "");
46 : for (i = 1; i <= qt; i++) _fbd_head[ar[i]] = 1; #行頭禁則文字種
47 : _TFCT = 0; #textf()用グローバルカウンタ
48 : _TFAR[1] = ""; #textf()用グローバル配列
49 : }
辞書に追加する項目(2byte ASCII以外の記号)があるので _asc[]をコピーします。
簡易的にワードラップと禁則処理を行いたいので、辞書を追加します。
次の関数で切り出した指定桁の文字列は、グローバル配列に順次格納していきます。この辺りは、必要とされる状況によって変わりますが、今回は即時吐き出しを行わず、貯めて吐き出す仕様としました。
※メモリを贅沢に使います。
50 : #. textf();文書を指定桁数で整形する(Shift_JIS/UTF-8)
51 : # str:対象文字列 col:桁数(表示長さ単位) mode:0 禁則処理+word wrap(0)
52 : function textf(str, col, mode, lenb, \
53 : ch, i, si, mbc, rp, rem) {
54 : if (col < 10) mode = 1; #col<4:行末禁則で無限ループ
55 : si = 1;
56 : while (ch = substr(str, ++i, 1)) {
57 : if (ch in _hfc) {
58 : lenb += 1;
59 : if (mbc) { mbc = 0; rp = i - 1; } #改行候補位置(2Bと1B境界)
60 : if (ch ~ /[ ]/) rp = i; #改行候補位置(スペース後)
61 : }
62 : else { lenb += 2; mbc = 1; }
63 :
64 : if (lenb < col) ;
65 : else if (lenb == col) { #ch:mbc/!mbc
66 : if (!mode) {
67 : if (!mbc && !(ch in _fbd_wrap) && si < rp) i = rp; #wrap
68 : if (substr(str, i, 1) in _fbd_end) i--; #行末禁(ch更新)
69 : else if (substr(str, i + 1, 1) in _fbd_head) i++; #行頭禁
70 : }
71 : _TFAR[++_TFCT] = substr(str, si, i - si + 1);
72 : si = i + 1; rp = lenb = 0;
73 : }
74 : else { #over ch:mbc
75 : if (!mode) {
76 : if (substr(str, i - 1, 1) in _fbd_end) i--; #行末禁
77 : else if (ch in _fbd_head) i++; #行頭禁
78 : }
79 : _TFAR[++_TFCT] = substr(str, si, i - si);
80 : si = i; rp = 0; lenb = 2; #over 次行繰り越し
81 : }
82 : } #while終了後 空行 or lenb<colのまま(残文有) or colピッタリ(残文無)
83 : (str) ? rem = substr(str, si) : _TFAR[++_TFCT] = "";
84 : if (rem) _TFAR[++_TFCT] = rem;
85 : }
_textf_init()で作成した辞書 _hfc を参照します。
文字位置を表す i, si, rp を使って切り出し位置と切り出す量を調整しています。
上述の bsubstr()/bsformat()と同じアルゴリズムです。
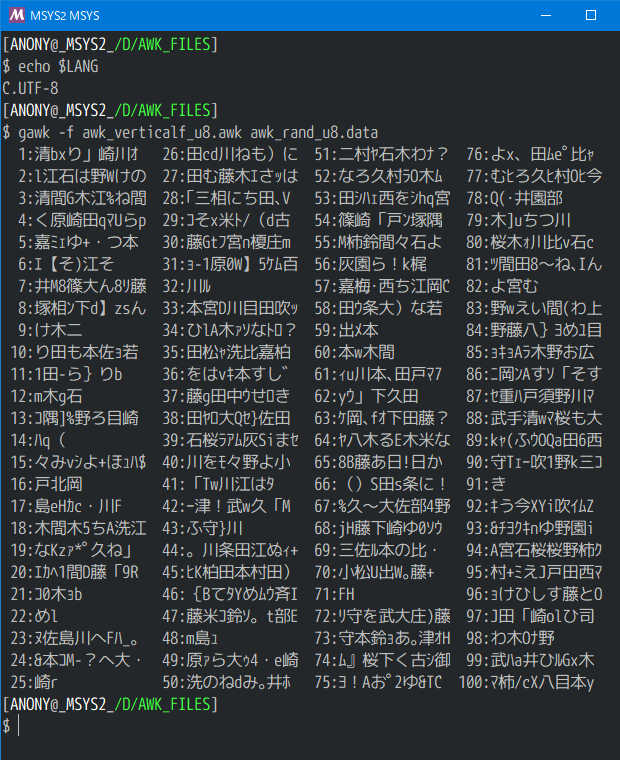
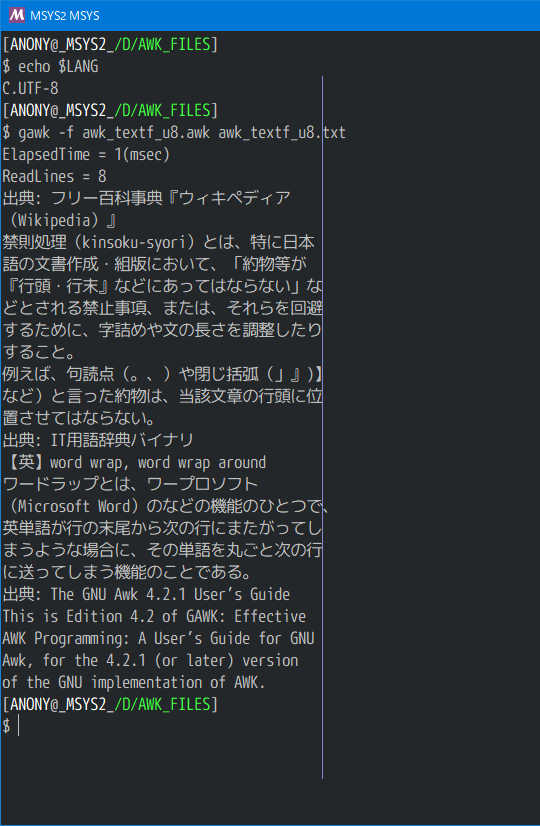
実行結果 #CmdLine : gawk414 -f awk_textf.awk awk_textf.txt
 GAWK for win32 3.1.5/4.1.4/4.2.1/5.0.0 で動作確認
UTF-8/MSYS2/GAWK5.0
GAWK for win32 3.1.5/4.1.4/4.2.1/5.0.0 で動作確認
UTF-8/MSYS2/GAWK5.0
 web上IDEの IDEONE.com(GAWK 4.1.3)でも動作確認した
_asc_init() を利用した blength(), bsubstr(), bsformat(), textf()
これらの関数を用いると、UTF-8でもShift_JISでも表示長は同一に扱える
web上IDEの IDEONE.com(GAWK 4.1.3)でも動作確認した
_asc_init() を利用した blength(), bsubstr(), bsformat(), textf()
これらの関数を用いると、UTF-8でもShift_JISでも表示長は同一に扱える
日英句読記号を含む全半角混成100文字/行(組成random) 10,000行を 40桁(表示長さ 40 ) Wordwrap/禁則処理あり で整形するのにかかった時間は、858ミリ秒(0.858秒)でした。ちなみに表示長さ 20 だと、951ミリ秒、表示長さ 80 だと、818ミリ秒です。数えるだけで 548ミリ秒(上述/今回も同等)かかるのですから、かなり良い数値だと思います。
重箱の隅だと思っていたらパンドラの箱だった
GAWK User’s Guide(テキスト部分)を整形実験していて、やたらとダブルクォートで引っかかると思ったら、超似ている変な記号でした(左/右(二重)引用符:シングル/ダブルクォートは前方と後方を区別していたらしい)。もっとあるかもと思いましたが、調べているとキリがないので、シングル/ダブルクォート似の4文字だけ辞書に追加しました。中にはShift_JISにないもの(en/emダッシュ)もあり、UTF-8の恐ろしさを垣間見た気がします。UTF-8/Shift_JISの追加半角辞書(2byte 文字)を作る必要性を感じました。UTF-8環境であれば、配列をつかってユニークな文字の一覧がすぐにできそうです。
The GNU Awk 4.2.1 User’s Guide.html 内の ASCII以外の使用文字を調べる
1 : #. awk_extract_char_u8.awk;
2 : # 欧文テキストからASCII以外の文字をユニーク抽出
3 : BEGIN {
4 : _asc_init();
5 : }
6 :
7 : {
8 : i = 0;
9 : while (ch = substr($0, ++i, 1)) samp[ch];
10 : ct += i - 1;
11 : }
12 :
13 : END {
14 : for (ch in samp) (ch in _asc) ? 0 : ret = ret ch;
15 :
16 : print "QTY of char : " ct;
17 : printf("Not ASCII char : [%s]\n", ret);
18 : }
19 : #. _asc_init();ASCII辞書
20 : function _asc_init( i, hk, ar, qt) {
21 : for (i = 0; i < 128; i++) _asc[sprintf("%c", i)] = i;
22 : }
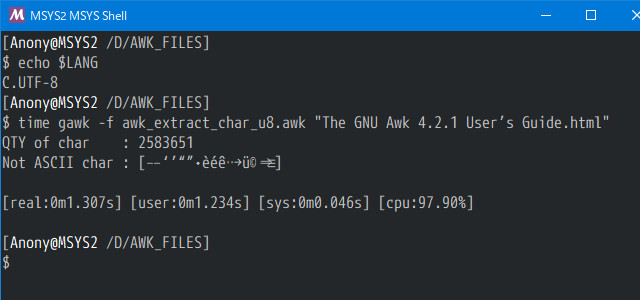
User's Guide に使用されている ASCII 以外の文字は、あまり多くはないようです。この文字群を辞書に登録すれば、対症療法的には良いのですが、どうしたものでしょう、なんか真ん中より右が怪しいです。
表示のみ拡大してみます。
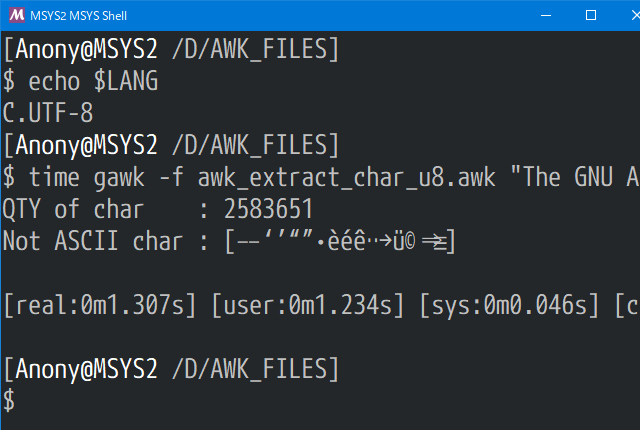
やっぱりおかしな感じです。 等幅フォント(monospace)で書き出してみます。
[…]が隣りの[→]と重なり、[⇒]が[≡]と重なってなんだかわからなくなっていました。MSYS2に設定しているフォントではうまく表せなかったようです。欧文フォント "Courier New" だとすべて半角で、きちんと見えました。
ところで、これ全部本当に半角扱いしていいのでしょうかね? 筆者の web環境では、等幅/monospace指示で全角がたくさんあるのですが。[⇒]と[…]なんて筆者的には全角にしたいところです。おそらく、筆者の使用しているフォントは、[⇒]と[…]に全角を割り当て、MSYS2が半角しか割り当てなかった不具合だろうと推測しています。
けれど、"Courier New" では全部半角で表示され、MSYS2の出力も半角です? 悩ましい。なんだこれ、厳密な規則はないのか? これが環境依存なのか。うちのフォントが全角というなら、[⇒]と[…]は全角で扱わないと表示長の整合性が取れなくなります。だから追加項目から除外する必要があります。というわけで、すべて半角文字とするわけにもいかなくなりました。ASCIIじゃなくなった途端にフォント(等幅)によって、表示長が変わってしまいます。普段から"Courier New"を使えということか...
行き詰まりました...OTL