GAWK 関数ヘッダコメントを自動生成する
マクロの概要
サクラエディタのマクロで、AWKソース専用です。関数のヘッダコメントのスケルトンをパラメータ付き(in/out)で挿入し、2回目以降は本体変更分を更新します。
記述様式と規則
#. 関数名:
# 戻値:
# パラメータ1:in/out:
# パラメータ2:in/out:
# パラメータ3:in/out:
.
.
.
# 概要説明等は自動記述部の下に記述(行数制限なし)
# 自動記述部の各行は複数行にマージできない
# 自動記述部への追記事項を含め、ユーザーが記述する文にコロン「:」は使用不可
# 空行はNG 削除される更新時、先頭の「#.」より上に書かれているコメントや空行に影響はありません。
in/out: その後の使用/不使用にかかわらず、パラメータが配列であり、その配列が関数内で左辺値として扱われるか、または delete される場合に out となります。
スケルトン生成後、本体のパラメータ名を変更、またはパラメータそのものを消去すると、更新時、自動記述部の下に「#MISSING!」という行が挿入されます。内容は、旧コメントのパラメータ名とユーザー記述データです。
パラメータを増加/並び替え、または関数名を変更、これらはそのまま反映されます。
GAWK4以上で動作します。
使用例
1つの関数のみヘッダコメント挿入
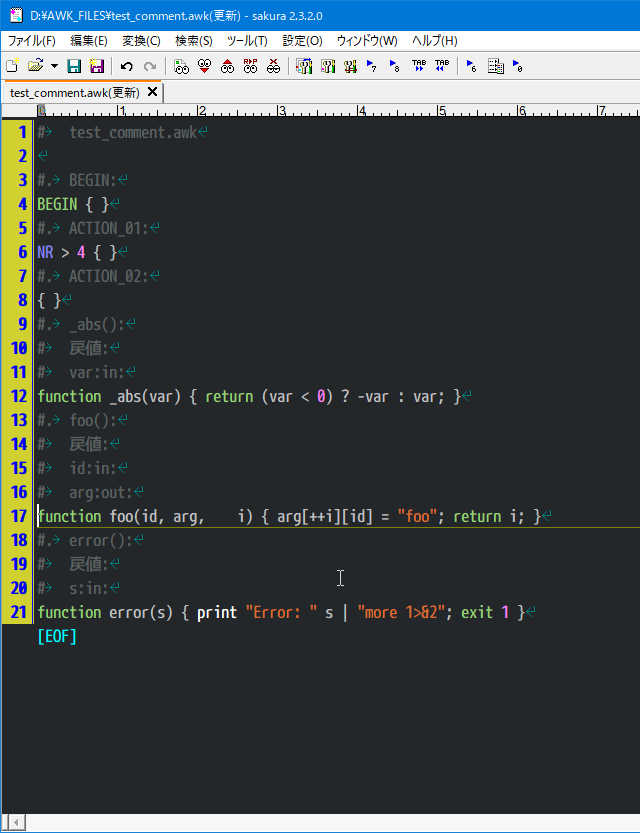
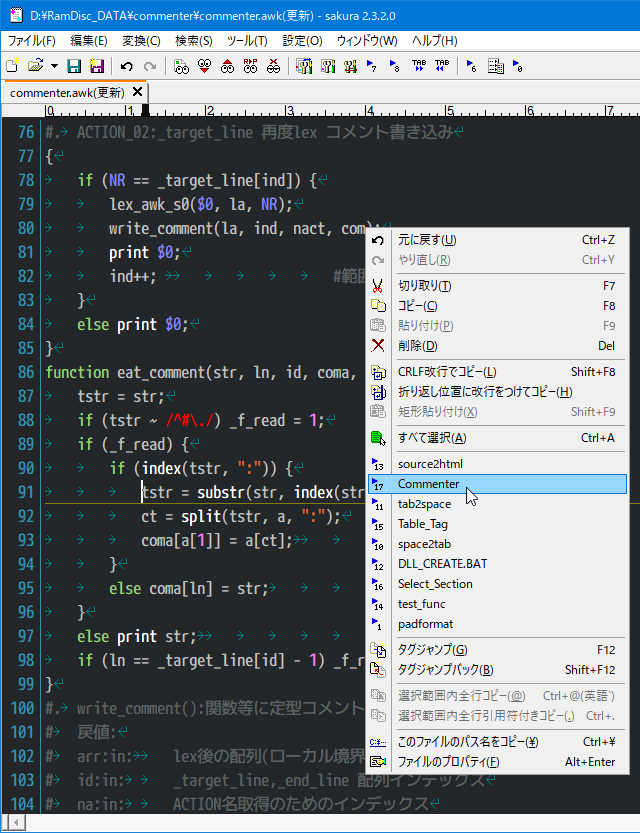 関数内のどこかを左クリック
右クリック、コンテキストメニューより「Commenter」を選択
関数内のどこかを左クリック
右クリック、コンテキストメニューより「Commenter」を選択
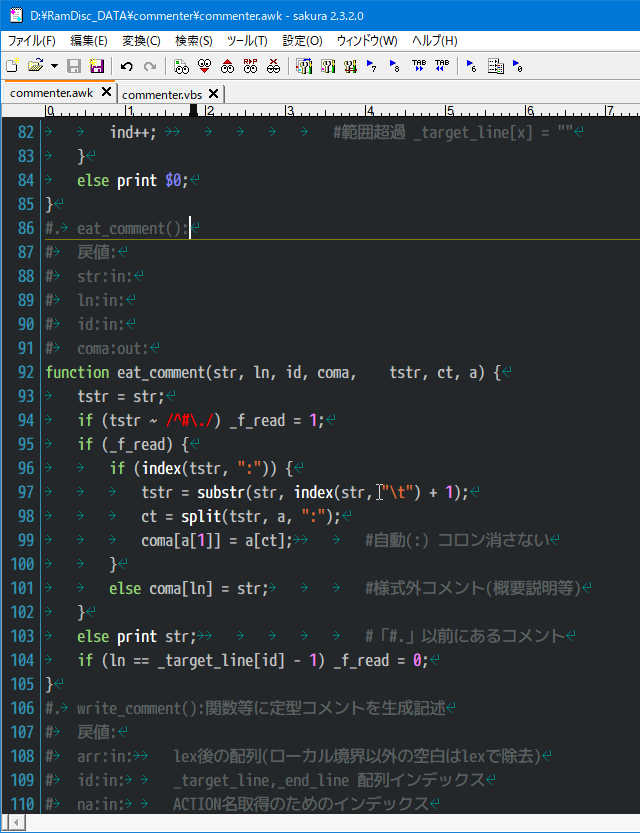 ヘッダコメントのスケルトンが挿入されカーソルがセットされる
パラメータ内の連続スペース3個以上でローカル変数との境界を認識する
タブでは認識しない(複数行のパラメータ参照)
一括挿入
ヘッダコメントのスケルトンが挿入されカーソルがセットされる
パラメータ内の連続スペース3個以上でローカル変数との境界を認識する
タブでは認識しない(複数行のパラメータ参照)
一括挿入
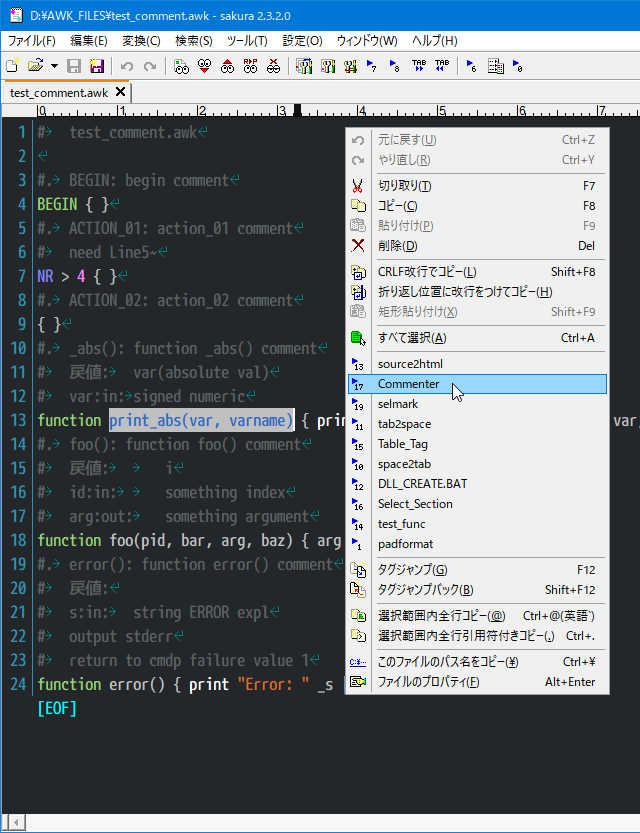
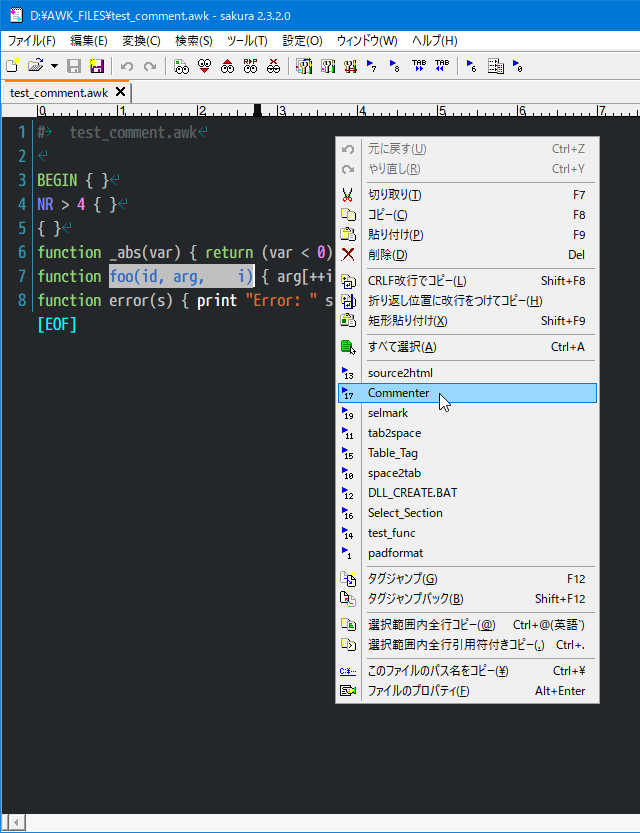 適当(function 行を選択した方が良い)に文字列を選択した状態で
「Commenter」を起動すると
適当(function 行を選択した方が良い)に文字列を選択した状態で
「Commenter」を起動すると
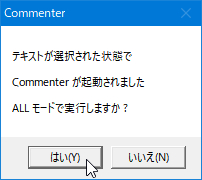 MsgBoxが現れ、ALLモード(全セクションにコメント挿入)にするか
問い合わせがあるので「はい」ならAllモード、「いいえ」なら
通常モード(カーソル行がターゲット)でコメントを挿入する
ここでは「はい」をクリック
MsgBoxが現れ、ALLモード(全セクションにコメント挿入)にするか
問い合わせがあるので「はい」ならAllモード、「いいえ」なら
通常モード(カーソル行がターゲット)でコメントを挿入する
ここでは「はい」をクリック
 全てのセクションに一括挿入される
return 文がない関数でも「戻値:」は必ず入るが
削除してはならない
ACTIONセクションには上から順に名前を付与(単独の挿入時も同名となる)
一括更新(コメント書き込み後に関数本体を変更した場合)
全てのセクションに一括挿入される
return 文がない関数でも「戻値:」は必ず入るが
削除してはならない
ACTIONセクションには上から順に名前を付与(単独の挿入時も同名となる)
一括更新(コメント書き込み後に関数本体を変更した場合)
 コメントを記述後 しばらくして
本体の関数名やパラメータを書き換えたとする
上記同様にALLモードで実行
コメントを記述後 しばらくして
本体の関数名やパラメータを書き換えたとする
上記同様にALLモードで実行
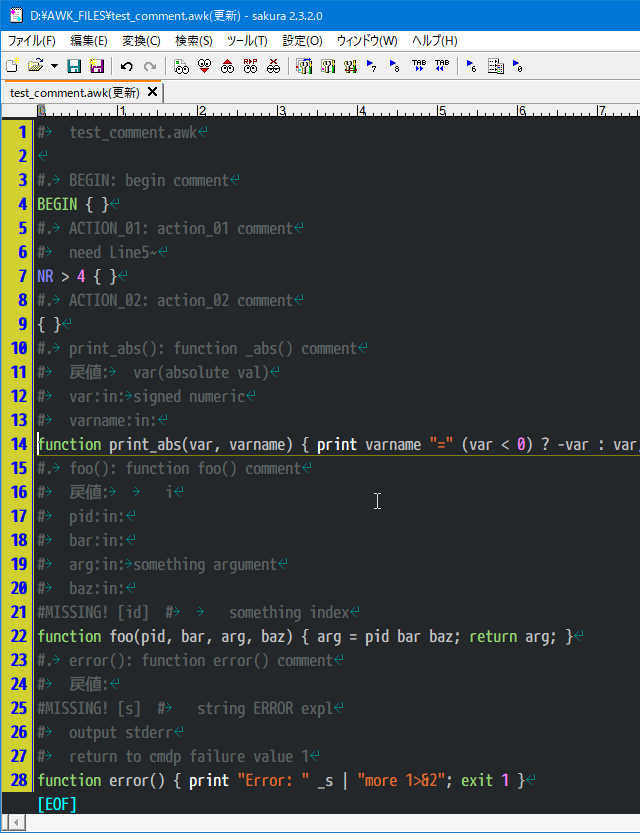 関数名変更やパラメータ増加/並びの変化は"更新"され
パラメータ名の消去/変更箇所は「#MISSING!」に記述される
in/outは実行されるたびに判定しなおす
冒頭の1関数のみの場合でも同様
パラメータが複数行にまたがる場合の注意点
関数名変更やパラメータ増加/並びの変化は"更新"され
パラメータ名の消去/変更箇所は「#MISSING!」に記述される
in/outは実行されるたびに判定しなおす
冒頭の1関数のみの場合でも同様
パラメータが複数行にまたがる場合の注意点
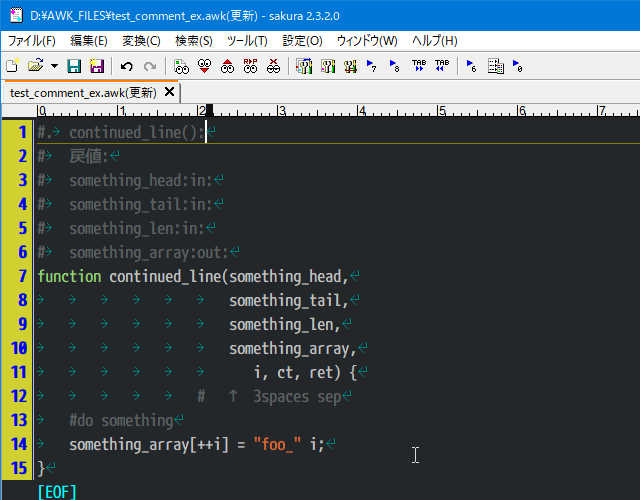 11行 スペースを入れてローカル変数を明示
3つ以上のスペースがない場合「)」が現れるまですべてを列挙する
11行 スペースを入れてローカル変数を明示
3つ以上のスペースがない場合「)」が現れるまですべてを列挙する
関数内のどこかを左クリック
右クリック、コンテキストメニューより「Commenter」を選択
ヘッダコメントのスケルトンが挿入されカーソルがセットされる
パラメータ内の連続スペース3個以上でローカル変数との境界を認識する
タブでは認識しない(複数行のパラメータ参照)
一括挿入
適当(function 行を選択した方が良い)に文字列を選択した状態で
「Commenter」を起動すると
MsgBoxが現れ、ALLモード(全セクションにコメント挿入)にするか
問い合わせがあるので「はい」ならAllモード、「いいえ」なら
通常モード(カーソル行がターゲット)でコメントを挿入する
ここでは「はい」をクリック
全てのセクションに一括挿入される
return 文がない関数でも「戻値:」は必ず入るが
削除してはならない
ACTIONセクションには上から順に名前を付与(単独の挿入時も同名となる)
一括更新(コメント書き込み後に関数本体を変更した場合)
コメントを記述後 しばらくして
本体の関数名やパラメータを書き換えたとする
上記同様にALLモードで実行
関数名変更やパラメータ増加/並びの変化は"更新"され
パラメータ名の消去/変更箇所は「#MISSING!」に記述される
in/outは実行されるたびに判定しなおす
冒頭の1関数のみの場合でも同様
パラメータが複数行にまたがる場合の注意点
11行 スペースを入れてローカル変数を明示
3つ以上のスペースがない場合「)」が現れるまですべてを列挙する
このマクロは、初めに各セクション/関数の全記述位置を解析しています。そのため、対象関数を含むすべてのセクション中、ひとつでも特定のエラー(中括弧が閉じられていない、正規表現の誤りがある等)がある場合、処理を中断、エラーを表示します。作りかけのスクリプトではご注意ください。
何らかの理由により、元に戻したい場合は、2回「元に戻す」を行ってください。1回だけだとファイル先頭行に数字(ジャンプ先)が残ります。
マクロの実装
commenter.vbs
1 : 'サクラマクロ commenter.vbs
2 : 'AWKファイル限定 関数/セクションに定型コメントを自動生成/更新
3 : '編集中のファイルはcommenter.awk の出力に全置換される
4 : '適当にテキストを選択後実行すると、一括挿入/更新モードに移行
5 :
6 : Option Explicit
7 : Const gawk = "gawk414 -v ARG1="
8 : Const awkfile = " -f y:\commenter\commenter.awk "
9 : Dim spath, slext, ncurline, arg, ntarget, scmd
10 : Dim fissel, sprpt, vans, fall, scurline
11 :
12 : sprpt = "テキストが選択された状態で" & vbCrLf & vbCrLf
13 : sprpt = sprpt & "Commenter が起動されました" & vbCrLf & vbCrLf
14 : sprpt = sprpt & "ALL モードで実行しますか ?"
15 : fall = False
16 :
17 : With Editor
18 : spath = .GetFileName
19 : slext = LCase(Mid(spath, InStrRev(spath,".") + 1))
20 : fissel =.IsTextSelected()
21 : End With
22 :
23 : If slext <> "awk" Then
24 : Call MsgBox("AWKファイルではありません",vbOKOnly, "Commenter")
25 : Else
26 : With Editor
27 : .FileSave 'must
28 : ncurline = .ExpandParameter("$y")
29 : arg = ncurline
30 :
31 : If Not fissel = 0 Then
32 : vans = MsgBox(sprpt,vbYesNo,"Commenter")
33 : If vans = vbYes Then
34 : arg = arg & ",1"
35 : fall = True
36 : End If
37 : End If
38 :
39 : .CancelMode 0
40 : .SelectLine
41 : scurline = .GetSelectedString(0)
42 : .CancelMode 0
43 :
44 : scmd = gawk & """" & arg & """" & awkfile & spath
45 : .SetDrawSwitch 0
46 : .SelectAll 'to replace all
47 : .ExecCommand scmd, 3 'output append
48 :
49 : .Jump 1,1 'gawk returns value this line
50 : .SelectLine 'it will delete next if
51 : ntarget = .GetSelectedString(0) 'line number or error message
52 :
53 : If IsNumeric(ntarget) = True Then
54 : .Delete
55 : If fall = True Then
56 : .Jump ntarget,1
57 : .SearchNext scurline 'adjust view if uniq
58 : .CancelMode 0
59 : .SearchClearMark
60 : .CurLineCenter
61 : Else
62 : .Jump ntarget,1
63 : .GoLineEnd
64 : .SetViewTop (ntarget - 5)
65 : End If
66 : Else
67 : .Undo 'error
68 : Call MsgBox(ntarget, vbOKOnly, "Commenter")
69 : End If
70 :
71 : .SetDrawSwitch 1
72 : .ReDraw 0
73 : End With
74 : End If
commenter.awk
BEGIN
1 : # commenter.awk;セクション及び関数にコメントを挿入 Ver0.7
2 : # 複数行のパラメータに対応 in/out自動判定
3 : # コメント一括挿入, 更新時既存コメントをリロケート
4 :
5 : #. BEGIN:エディタカーソル位置から現在セクションを把握
6 : BEGIN {
7 : _lex_init();
8 : _infoproc_init();
9 : _comment_init();
10 :
11 : ct = split(ARG1, a, ",");
12 : if (ct > 1) { curline = a[1]; _fall = 1; }
13 : else { curline = ARG1; _fall = 0; }
14 :
15 : while (getline < ARGV[1] > 0) {
16 : ++vnr;
17 : lex_awk_s0($0, lexa, vnr);
18 :
19 : #同期ソース(コメント/リテラル/正規表現省略)空白無視 パラメータ境界有
20 : st = "";
21 : for (i in lexa)
22 : if (i != 1 && lexa[i][0] == "i" && lexa[i - 1][0] == "i")
23 : st = st " " lexa[i][1];
24 : else st = st lexa[i][1];
25 : _src[vnr] = st;
26 :
27 : #記述位置解析
28 : if (retval = infoproc(lexa, vnr, sections)) {
29 : (retval == 1) ? errec = vnr - 1 : errec = retval;
30 : split(_csv, a, ",");
31 : errstr = a[1] ": line " errec;
32 : break;
33 : }
34 : }
35 : close(ARGV[1]);
36 :
37 : if (_erct) { #lex_awk_s0()エラー
38 : for (n in _er) print _er[n] > "/dev/stderr";
39 : exit 1;
40 : }
41 : else if (retval) { #infoproc()エラー
42 : print "ERROR: " errstr > "/dev/stderr";
43 : exit 1;
44 : }
45 : else if (_cb) { #EOF直前のエラー(閉じられていない中括弧)
46 : split(_csv, a, ",");
47 : errstr = a[1] ": line " vnr;
48 : print "ERROR: " errstr > "/dev/stderr";
49 : exit 1;
50 : }
51 :
52 : sect_div_f(sections, vnr, _result);
53 :
54 : for (n in _result) #現在関数把握(tl)
55 : if (curline >= _result[n][0] && curline <= _result[n][2]) {
56 : _start_line[1] = _result[n][0]; #関数開始行
57 : tl = _target_line[1] = _result[n][3]; #関数宣言行
58 : _end_line[1] = _result[n][2]; #関数終了行
59 : nact = n;
60 : done = 1;
61 : break;
62 : }
63 :
64 : if (_fall) { #コメント一括
65 : for (n in _result) {
66 : _start_line[n] = _result[n][0];
67 : _target_line[n] = _result[n][3];
68 : _end_line[n] = _result[n][2];
69 : }
70 : done = 1;
71 : }
72 :
73 : if (!done) { #カーソルが改行後のEOF直前に置かれている
74 : print "ERROR: Cursor position out of range." > "/dev/stderr";
75 : exit 1;
76 : }
77 : ind = 1;
78 : print tl; #1行目に書き込む(マクロで削除)
79 : }ACTION_01
80 : #. ACTION_01:既存のコメントを読む
81 : NR >= _start_line[ind] && NR < _target_line[ind] {
82 : eat_comment($0, NR, ind, com);
83 : next;
84 : }ACTION_02
85 : #. ACTION_02:コメント書き込み/更新
86 : {
87 : if (NR == _target_line[ind]) {
88 : lex_awk_s0(gets_src(NR), la, NR); #同期ソースから入力
89 : write_comment(la, ind, nact, com);
90 : print $0;
91 : ind++; #範囲超過 _target_line[x] = ""
92 : }
93 : else print $0;
94 : }_comment_init()
95 : #. _comment_init():コメント内作業のマクロ的glb変数
96 : # 戻値:
97 : function _comment_init() {
98 : DLM = ":"; #コメント区切り文字
99 : REG = "\\[[^;]+\\]=[^=]|\\ydelete "; #左辺配列代入と削除
100 : }gets_src()
101 : #. gets_src():同期ソース(_src)から現在行の文字列を取得
102 : # 戻値: 文字列
103 : # line:in: 行番号
104 : # 関数の場合はパラメータ終端まで文字列(行)を繋ぐ
105 : function gets_src(line, str, pos, c) {
106 : if (_src[line] !~ /^(func |function )/) return _src[line];
107 :
108 : while (!pos) {
109 : pos = index(_src[line], ")"); #パラメータ列挙終端
110 : str = str _src[line++];
111 : if (++c > 100) break; #無限ループ回避
112 : }
113 : return str;
114 : }eat_comment()
115 : #. eat_comment():既存のコメントを読み、記録
116 : # 戻値:
117 : # str:in: $0
118 : # ln:in: NR
119 : # id:in: _target_line インデックス
120 : # coma:out: コメント記録用配列 >write_comment()
121 : function eat_comment(str, ln, id, coma, ct, a) {
122 : if (str ~ /^#\./) _f_read = 1;
123 :
124 : if (_f_read) { #データレコード化
125 : if (index(str, DLM)) { #規定様式 記号「:」
126 : sub(/^#\.?[ \t]*/, "", str);
127 : ct = split(str, a, DLM);
128 : coma[a[1]] = a[ct]; #coma["名前"]=ユーザー追記
129 : }
130 : else if (str ~ /^$/) ; #空行 削除
131 : else coma[ln] = str; #様式外 coma["行番号"]=ユーザー下部記述
132 : }
133 : else print str; #「#.」以前にあるコメント
134 :
135 : if (ln == _target_line[id] - 1) _f_read = 0;
136 : }write_comment()
137 : #. write_comment():定型ヘッダコメントを生成記述/更新
138 : # 戻値:
139 : # arr:in: lex後の配列(ローカル境界以外の空白はlexで除去)
140 : # id:in: _target_line,_end_line 配列インデックス
141 : # na:in: ACTION名取得のためのインデックス
142 : # coma:out: コメント記録用配列 <eat_comment()
143 : # 簡易解析 in/out
144 : # 更新時 既存コメントのユーザー追記部、下部自由記述を再配置
145 : # パラメータ名変更/消去分は「#MISSING!」行を出力
146 : function write_comment(arr, id, na, coma, ct, i, j,\
147 : section, fname, param, dreg, io) {
148 : ct = length(arr);
149 : section = arr[1][1];
150 : if (section ~ /^BEGIN|^END/) {
151 : print "#.\t" section DLM coma[section]; #ユーザー追記
152 : delete coma[section]; #書いたら消す
153 : }
154 : else if (section ~ /^function$|^func$/) {
155 : fname = arr[2][1] "()"; #arr[2][1] funcname
156 : for (i in coma) if (i ~ /\(\)$/) break; #追記部 不動
157 : print "#.\t" fname DLM coma[i];
158 : delete coma[i];
159 :
160 : print "#\t戻値" DLM coma["戻値"];
161 : delete coma["戻値"];
162 :
163 : for (i = 4; i <= ct; i++) { #i=4 第1パラメータ
164 : if (arr[i][0] ~ /s/) break; #ローカル変数境界
165 : if (arr[i][1] ~ /\)/) break;
166 : if (arr[i][0] ~ /i/) {
167 : param = arr[i][1];
168 : dreg = "\\y" param REG param "\\y"; #dynamic regexp
169 : io = "in";
170 : #パラメータ 代入/削除の簡易解析(同期ソース _src)
171 : for (j = _target_line[id]; j <= _end_line[id]; j++)
172 : if (match(_src[j], dreg)) { io = "out"; break; }
173 : print "#\t" param DLM io DLM coma[param];
174 : delete coma[param];
175 : }
176 : }
177 : }
178 : else { #ACTION
179 : if (_fall) na = id;
180 : #BEGIN infoproc()で命名 sect_div_f()で配列化 _result[id][1]
181 : for (i in coma) if (i ~ /^ACTION/) break; #追記部 不動
182 : print "#.\t" _result[na][1] DLM coma[i];
183 : delete coma[i];
184 : }
185 : #comaに残っているデータレコードの処理
186 : PROCINFO["sorted_in"] = "@ind_num_asc"; #行番号のため
187 : for (i in coma)
188 : if (coma[i] ~ /^#/) print coma[i]; #ユーザー下部記述
189 : else print "#MISSING! [" i "] #" coma[i]; #パラメータ名変更/消去
190 : delete coma;
191 : }_lex_init()
192 : #. _lex_init():正規表現判定用区切り文字/演算子辞書
193 : # 戻値:
194 : function _lex_init( ct, ar, i, prev, op1, op2, a_z) {
195 : prev = "(.,.~.!~.==.!=.first.case.@.!.=.&&.||";
196 : op1 = "+,-,*,/,^,%,!,~,=,<,>,?,@"
197 : op2 = "++,--,+=,-=,*=,/=,%=,^=,!~,==,!=,<=,>=,&&,||,>>,<<";
198 : # lex 識別子 正規表現 /[a-zA-Z_]/ と /[a-zA-Z0-9_]/ の代替
199 : # 高速化のためのハッシュテーブル
200 : a_z = "a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,\
201 : A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,_,$";
202 : ct = split(a_z, ar, ",");
203 : for (i = 1; i <= ct; i++) {
204 : _a_9[ar[i]];
205 : }
206 : for (i = 0; i < 10; i++) _a_9[i];
207 :
208 : ct = split(prev, ar, ".");
209 : for (i = 1; i <= ct; i++) _prev[ar[i]];
210 :
211 : ct = split(op1, ar, ",");
212 : for (i = 1; i <= ct; i++) _op1[ar[i]];
213 :
214 : ct = split(op2, ar, ",");
215 : for (i = 1; i <= ct; i++) _op2[ar[i]];
216 :
217 : _infunc = _inparam = 0; #関数/パラメータフラグglb変数
218 : delete _er[0]; _erct = 0; #エラー用glb変数
219 : _cont_ch = ""; #リテラルか正規表現の持越し用glb変数
220 : }lex_awk_s0()
221 : #. lex_awk_s0():粗レキシカルアナライザ
222 : # 戻値: トークン数(resの要素数)
223 : # str:in: 1行のAWKソース
224 : # res:out: 2次元配列 res[x][0]=属性 res[x][1]=トークン
225 : # vnr:in: 現在行
226 : # コメント/リテラル/正規表現 省略 空白無視(パラメータ内連続space 認識)
227 : function lex_awk_s0(str, res, vnr, len,\
228 : once, fcon, i, ib, ch, prev,\
229 : pos, ct, tmp, ret) {
230 : ct = i = 1;
231 : prev = "first"; #行頭 直前字句
232 : delete res; #初期化
233 :
234 : len = length(str);
235 : if (!len) { res[1][0] = "e"; res[1][1] = ""; return 1; } #空行
236 : if (substr(str, len) ~ /\\/) fcon = 1; #継続フラグ
237 :
238 : while (i <= len) {
239 : ch = substr(str, i, 1); #一文字切り出す
240 : ib = i; #ib 切り出し開始位置
241 :
242 : #複数行にまたがる正規表現/リテラル 前行引き継ぎ
243 : if (!once) #1度だけ実行
244 : if (!_cont_ch) once = 1;
245 : else { once = 1; ch = _cont_ch; } #i=1 " or /
246 :
247 : if (ch in _a_9) ch = "z"; #正規表現の代替
248 :
249 : switch (ch) {
250 : case /\t/: #タブ(無視)
251 : while (tmp = substr(str, ++i, 1))
252 : if (tmp !~ /\t/) break;
253 : continue;
254 : case / /: #空白
255 : while (tmp = substr(str, ++i, 1))
256 : if (tmp !~ / /) break;
257 : if (i - ib > 2) {
258 : if (_inparam) { #ローカル変数境界
259 : ret = " ";
260 : res[ct][0] = "s";
261 : break;
262 : }
263 : else continue;
264 : }
265 : else continue;
266 : case /z/: #識別子
267 : while (tmp = substr(str, ++i, 1)) #次の文字から(++i)
268 : if (!(tmp in _a_9)) break; #正規表現の代替
269 : ret = prev = substr(str, ib, i - ib);
270 : res[ct][0] = "i";
271 : (ret ~ /^function$|^func$/) ? _infunc = 1 : 0;
272 : break;
273 : case /"/: #文字列リテラル
274 : pos = litendpos(str, i);
275 : if (pos) { i = ++pos; _cont_ch = ""; } #両端の””含む
276 : else if (fcon) { i = len; _cont_ch = "\""; } #継続
277 : else if (_cont_ch ~ /"/ && str ~ /^"/) {
278 : i = 2; #被継続 行頭" (fonetime参照)
279 : _cont_ch = ""; #被継続解除
280 : }
281 : else { #エラー
282 : err(vnr, i);
283 : i++;
284 : _cont_ch = "";
285 : }
286 : ret = prev = "\"-\"";
287 : res[ct][0] = "l";
288 : break;
289 : case /\//: #正規表現または除算演算子
290 : if (prev in _prev) { #正規表現定数
291 : pos = regendpos(str, i);
292 : if (pos) { i = ++pos; _cont_ch = ""; }
293 : else if (fcon) { i = len; _cont_ch = "/"; }
294 : else if (_cont_ch ~ /\// && str ~ /^\//) {
295 : i = 2;
296 : _cont_ch = "";
297 : }
298 : else {
299 : err(vnr, i);
300 : i++;
301 : _cont_ch = "";
302 : }
303 : ret = prev = "/-/";
304 : res[ct][0] = "r";
305 : break;
306 : }
307 : else { #除算演算子
308 : i++;
309 : ret = prev = ch;
310 : res[ct][0] = "o";
311 : break;
312 : }
313 : case /#/: #コメント
314 : i = len + 1; #ループ強制終了
315 : ret = "#-"; #残余文字列全て
316 : res[ct][0] = "c";
317 : break;
318 : case /\(/:
319 : i++;
320 : ret = prev = ch;
321 : res[ct][0] = "p";
322 : if (_infunc) _inparam = 1;
323 : break;
324 : case /\)/:
325 : i++;
326 : ret = prev = ch;
327 : res[ct][0] = "p";
328 : if (_inparam) _infunc = _inparam = 0;
329 : break;
330 : default: #演算子/句読記号
331 : ret = prev = ch;
332 : if (ch in _op1) res[ct][0] = "o"; #演算子
333 : else res[ct][0] = "p"; #句読記号
334 : tmp = substr(str, i, 2); #2文字演算子かも
335 : i++;
336 : if (tmp in _op2) {
337 : ret = prev = tmp; #書き換え
338 : res[ct][0] = "o";
339 : i++;
340 : }
341 : break;
342 : }
343 : res[ct++][1] = ret; #トークン格納
344 : }
345 : return ct - 1; #切り出したトークン数
346 : }litendpos()
347 : #. litendpos():右ダブルクォートの正確な位置を返す(C/AWK)
348 : # 戻値: 右ダブルクォート位置
349 : # str:in: 文字列
350 : # pos:in: 左ダブルクォート位置
351 : function litendpos(str, pos, rpos, escape, ch) {
352 : rpos = escape = 0;
353 : while (ch = substr(str, ++pos, 1)) { #posの次文字から
354 : if (rpos) break;
355 : switch (ch) {
356 : case /\\/:
357 : (escape) ? escape = 0 : escape = 1; #偽 フラグ設定
358 : break;
359 : case /"/:
360 : (escape) ? escape = 0 : rpos = pos; #偽 終端
361 : break;
362 : default:
363 : (escape) ? escape = 0 : 0; #真 フラグ解除
364 : break;
365 : }
366 : }
367 : return rpos;
368 : }regendpos()
369 : #. regendpos():正規表現末尾の正確な位置を返す(AWK)
370 : # 戻値: 正規表現終端位置(右スラッシュ位置)
371 : # str:in: 文字列
372 : # pos:in: 左スラッシュ位置
373 : function regendpos(str, pos, rpos, escape, bracket, ch) {
374 : rpos = escape = bracket = 0;
375 : while (ch = substr(str, ++pos, 1)) { #posの次文字から
376 : if (rpos) break;
377 : switch (ch) {
378 : case /\\/:
379 : (escape) ? escape = 0 : escape = 1; #偽 Eフラグ設定
380 : break;
381 : case /\[/:
382 : (escape) ? escape = 0 : bracket = 1; #偽 Bフラグ設定 [ 内 ]
383 : break;
384 : case /]/:
385 : (escape) ? escape = 0 : bracket = 0; #偽 Bフラグ解除 [ ]外
386 : break;
387 : case /\//:
388 : (escape || bracket) ? escape = 0 : rpos = pos; #両フラグ 0
389 : break;
390 : default:
391 : (escape) ? escape = 0 : 0; #真 Eフラグ解除
392 : break;
393 : }
394 : }
395 : return rpos;
396 : }err()
397 : #. err():リテラル/正規表現のエラー
398 : # 戻値:
399 : # line:in: エラー行
400 : # pos:in: エラー桁 ※TAB 1文字
401 : function err(line, pos) {
402 : _er[++_erct] = "Error line: " line " position: " pos;
403 : }_infoproc_init()
404 : #. _infoproc_init():特に必要ないが変数チェックに使う
405 : # 戻値:
406 : function _infoproc_init() {
407 : _sectct = 0; #セクション/関数の合計数
408 : _csv = ""; #セクション/関数名,宣言行,開始行,終了行
409 : _cb = 0; #カーリーブラケット開閉数
410 : _fnamed = 0; #セクション名の有無
411 : _panum = 0; #Actionセクション名の一部
412 : _lastline = 0; #sect_div()が使用;
413 : }infoproc()
414 : #. infoproc():セクションと関数の位置(行)を取得
415 : # 戻値: エラーコード
416 : # lexa:in: レキシカルアナライザが吐き出した配列
417 : # lnr:in: 現在行
418 : # sections:out: sections[]=セクション/関数名,宣言行,開始行,終了行
419 : function infoproc(lexa, lnr, sections, ct, i, tok, ci) {
420 : ct = length(lexa);
421 : for (i = 1; i <= ct; i++) {
422 : tok = lexa[i][1];
423 : if (tok ~ /^BEGIN$|^BEGINFILE$|^END$|^ENDFILE$|^func$|^function$/) {
424 : if (_cb) return 1;
425 : _fnamed = 1; #セクション/関数名がある
426 : switch (tok) {
427 : case /BEGIN|END/:
428 : _csv = tok "," lnr;
429 : break;
430 : case /func/:
431 : for (ci = i + 1; ci <= ct; ci++)
432 : if (lexa[ci][0] !~ /w/) break;
433 : _csv = lexa[ci][1] "()" "," lnr; #関数名
434 : break;
435 : default:
436 : break;
437 : }
438 : }
439 : else if (tok ~ /^{$/) { #section/function { 本文開始行
440 : _cb++;
441 : if (_cb == 1) { # 0 → 1
442 : if (!_fnamed) #Actionに上から順に名前を付与
443 : _csv = sprintf("ACTION_%02d,%d", ++_panum, lnr);
444 : _csv = _csv "," lnr;
445 : }
446 : }
447 : else if (tok ~ /^}$/) { #section/function } 終了行
448 : _cb--;
449 : if (!_cb) { #1 → 0
450 : sections[++_sectct] = _csv "," lnr;
451 : _fnamed = 0;
452 : }
453 : else if (_cb < 0) return lnr;
454 : }
455 : }
456 : return 0;
457 : }sect_div_f()
458 : #. sect_div_f():infoproc() _sections[]からs_div[][]を作成
459 : # 戻値:
460 : # sect:in: _sections[] infoproc()が作成するglb配列
461 : # fnr:in: 最終行番号
462 : # s_div:out: [i][0] 開始行 [i][1] 名前 [i][2] 終了行 [i][3] 宣言行
463 : # infoproc()はセクション外を考慮していない sect_div_f()はこれを補完
464 : function sect_div_f(sect, fnr, s_div, csva, ct, i) {
465 : ct = length(sect);
466 : for (i = 1; i <= ct; i++) {
467 : split(sect[i], csva, ",");
468 : if (i == 1) {
469 : s_div[1][0] = 1;
470 : s_div[1][1] = csva[1];
471 : _lastline = s_div[1][2] = csva[4];
472 : s_div[1][3] = csva[2];
473 : }
474 : else {
475 : s_div[i][0] = _lastline + 1;
476 : s_div[i][1] = csva[1];
477 : _lastline = s_div[i][2] = csva[4];
478 : s_div[i][3] = csva[2];
479 : }
480 : }
481 : s_div[ct][2] = fnr; #最後の関数(セクション)はEOFまで
482 : }