GAWK 最長データに合わせてタブを補完する
データに新規データを継ぎ足す際に、最長データに合わせて次データ先頭が綺麗に揃っていると、見やすく、誤認しにくいです。スペースを補完して揃える方法は既に別ページで行っていますが、対象データ内部にタブがある場合、残念ながら揃いません。筆者作のblength()等はタブを半角1文字として扱っていますので、仕方ないのです。この場合は元データのタブをスペースに変換して出力するしかありません。
このページでは、元データをいじらずに、タブはタブのまま整然と揃える方法を考えてみました。
以下のテキスト各行に文字列データを追加します。(1行目と最終行タブ区切り/タブ幅4)
compl_tab.txt
a ab cde fg hi jkl mn
ab
abc
abcd
abcde
abcdef
abcdefg
abcdefgh
abcdefghi
abcdefghijklmnopqrstuvwxyz
abcdefghijklmnopqrstuvwxy
abcdefghijklmnopqrstuvwx
abcdefghijklmnopqrstuvw
abcdefghijklmnopqrstuv
英数混在ab123
ハンカク混在
function foo(bar) {return bar * 2;}
AWKが仲魔になった
コンゴトモヨロシク オマエマルカジリ
実行結果
Shift_JIS/tabs4
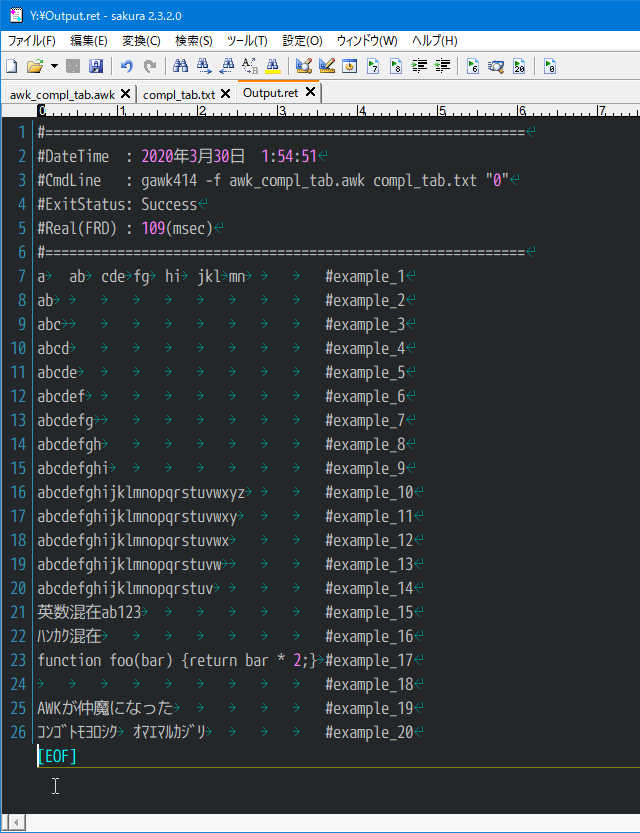 UTF-8/MSYS2/GAWK5.0.1/tabs4
UTF-8/MSYS2/GAWK5.0.1/tabs4
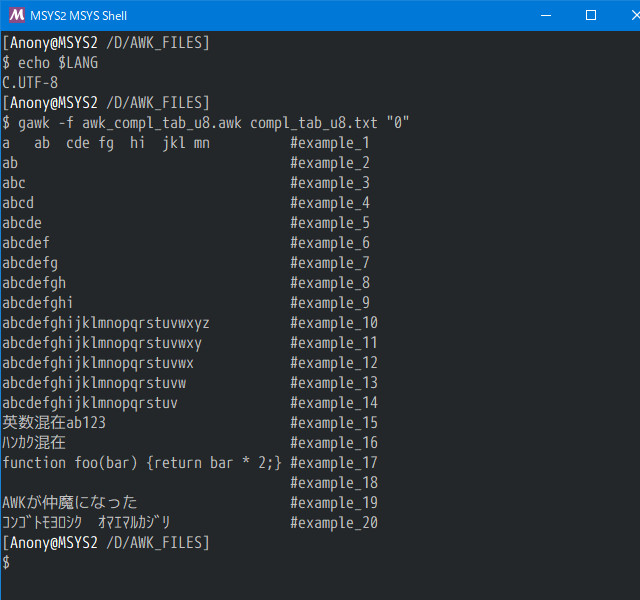
UTF-8/MSYS2/GAWK5.0.1/tabs4
- 考え方の骨子
- 元データの表示長を数える際、内包されているタブをスペース(長さ可変)に見たてて数える
- データ末尾にタブを1つ足した長さを表示長とする(最長データとの差:タブ幅の整数倍)
- 各行のデータ表示長を配列に記録しながら最長データを求める
- 全元データに「整数(倍) + 1」 のタブを補完する
awk_compl_tab.awk
BEGINFILE
1 : # awk_compl_tab.awk: 最長データに合わせて水平タブを補完
2 : # usage:awk -f awk_compl_tab.awk file "0" "4"
3 : # "0":$0 "4":タブ表示幅4 両方省略可
4 :
5 : #. BEGINFILE: 引数を使う(ARGV[2]/ARGV[3])
6 : BEGINFILE {
7 : if (ERRNO) nextfile;
8 : }BEGIN
9 : #. BEGIN: 最長データ+タブ1個の表示長を求める
10 : BEGIN {
11 : idx = ARGV[2];
12 : if (idx == "") idx = 1; #デフォルトターゲット $1
13 : tabs = ARGV[3];
14 : if (!tabs) tabs = 4; #デフォルトタブ幅 4
15 : _asc_init();
16 : dmax = _tab_init(ARGV[1], arr, idx, tabs);
17 : }ACTION_01
18 : #. ACTION_01: タブを補完し、新規データを揃える
19 : FILENAME == ARGV[1] {
20 : print $idx compl_tab(arr[NR], dmax, tabs) "#example_" NR;
21 : }_tab_init()
22 : #. _tab_init(): タブ初期化とデータの表示長(タブ内包)格納
23 : # 戻値: 最長データ+タブ1表示長
24 : # file:in: ファイル
25 : # ar:out: 全対象データ表示長 格納用配列
26 : # ind:in: フィールドインデックス
27 : # tablen:in: タブ表示幅
28 : # 最大表示長との差 76 (4タブ時)まで
29 : function _tab_init(file, ar, ind, tablen, max,
30 : ct, lenb, str, pos) {
31 : TABS = "\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t";
32 : while (getline < file > 0) {
33 : lenb = 0;
34 : str = $ind;
35 : do {
36 : if (pos = index(str, "\t")) { #タブ内包の表示長
37 : lenb += blength(substr(str, 1, pos - 1));
38 : lenb += tablen - lenb % tablen;
39 : str = substr(str, pos + 1); #既読部切り捨て
40 : }
41 : else lenb += blength(str);
42 : } while (pos)
43 : lenb += tablen - lenb % tablen; #データ+タブ1個の表示長
44 : ar[++ct] = lenb;
45 : if (max < lenb) max = lenb;
46 : }
47 : close(file);
48 : return max; #最長データ+タブ1個の表示長
49 : }compl_tab()
50 : #. compl_tab():最長データに合わせてタブを補完
51 : # 戻値: 補完タブ(文字列)
52 : # len:in: データ表示長
53 : # maxlen:in: 最長データ表示長
54 : # tablen:in: タブ表示幅
55 : function compl_tab(len, maxlen, tablen) {
56 : return substr(TABS, 1, (maxlen - len) / tablen + 1);
57 : }_asc_init()
58 : #. _asc_init():ASCII+半角カナ辞書(Shift_JIS)
59 : # 戻値:
60 : function _asc_init( i, hk, ar, qt) {
61 : for (i = 0; i < 128; i++) _asc[sprintf("%c", i)] = i;
62 : hk = "。「」、・ヲァィゥェォャュョッーアイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワン゙゚";
63 : qt = split(hk, ar, "");
64 : for (i = 1; i <= qt; i++) _asc[ar[i]] = 160 + i; #Shift_JIS
65 : _SCLP = " "; #マルチバイト文字の断片を表す文字
66 : }blength()
67 : #. blength():文字列長さ疑似バイトを返す(辞書_asc)
68 : # 戻値: 表示長さ
69 : # str:in: 文字列
70 : function blength(str, i, ch, lenb) {
71 : while (ch = substr(str, ++i, 1))
72 : (ch in _asc) ? lenb += 1 : lenb += 2;
73 : return lenb + 0;
74 : }