GAWK4.2.1 本体の printf() を改変する
筆者は、永らく GAWK3.1.5 for Windows 日本語対応版を愛用してきました。その便利さに慣れてしまい、 GAWK4.0.0 以降の printf()/sprintf() の文字列整形関連の中途半端さに耐えられず、DLL(extension)を作成していたわけですが、どちらかというと GAWK4 本体を手直ししたほうが、精神衛生上健全なのではないかと思いなおし、ちょっと本気で buitin.c を読んでみた次第です。
症状と手直しする場所
printf("%20.15s", str) は、str (アルファベットや数値等)を列幅20の中に右寄せで、最大15文字を出力する文字列整形命令です。str が15文字を超過していれば、16文字目以降は表示されず切り捨てられる仕組みとなっています。しかし、str に日本語が混じると、列幅が豪快にみだれてしまい、文字列整形の目的を達することはできなくなります。
原因は文字の表示長さの違いです。「abc」の三文字と「あい」の二文字では、「あい」のほうが表示長さは長く、半角を1単位とすると前者は3、後者は4となります。Windows-Shift_JIS(文字セット)の環境では、これが各バイト数と一致します。これを踏まえて改変に取り組みます。
ターゲットは GAWK4.2.1 for win32 (ezwinportsさん) の ソース buitin.c です。
printf()/sprintf() のフォーマット部分をつかさどるのは format_tree() という関数で、builtin.c 638行から始まり、1619行で終わっています。およそ1,000行のコードですので読むのも大変です。
format_tree()内で文字列整形出力にかかる「 "%〇.〇s" 」について書かれている部分は、「case 's':」1142行付近からです。
case 's': (format_tree switch)
1142 : case 's':
1143 : need_format = false;
1144 : parse_next_arg();
1145 : arg = force_string(arg);
1146 : if (fw == 0 && ! have_prec)
1147 : prec = arg->stlen;
1148 : else {
1149 : char_count = mbc_char_count(arg->stptr, arg->stlen);
1150 : if (! have_prec || prec > char_count)
1151 : prec = char_count;
1152 : }
1153 : cp = arg->stptr;
1154 : goto pr_tail;
fw:列幅(field widths)と prec:最大表示文字数(precision)のどちらか、またはどちらも記述されていたら1149行が実行されます。fw , prec ともに半角(バイト)を基準としています。
1149行目で、文字列のカウント方法をマルチバイト(全角も半角も1とする)としていますので、これを半角(バイト)でカウント(全角を2 半角を1)するように変更します。
旧1149 : char_count = mbc_char_count(arg->stptr, arg->stlen);
新1149 : char_count = arg->stlen;これで半角基準になりました。
1154行目の goto pr_tail; を追います。
ラベル pr_tail:
1451 : pr_tail:
1452 : if (! lj) {
1453 : while (fw > prec) {
1454 : bchunk_one(fill);
1455 : fw--;
1456 : }
1457 : }
1458 : copy_count = prec;
1459 : if (fw == 0 && ! have_prec)
1460 : ;
1461 : else if (gawk_mb_cur_max > 1) {
1462 : if (cs1 == 's') {
1463 : assert(cp == arg->stptr || cp == cpbuf);
1464 : copy_count = mbc_byte_count(arg->stptr, prec);
1465 : }
1466 : /* prec was set by code for %c */
1467 : /* else
1468 : copy_count = prec; */
1469 : }
1470 : bchunk(cp, copy_count);
1471 : while (fw > prec) {
1472 : bchunk_one(fill);
1473 : fw--;
1474 : }
1475 : s0 = s1;
1476 : break;
1461-1469行目 文字列にマルチバイト文字が使われていて、フォーマット指定子が 's' であったなら、カウント方法をマルチバイトとする、と書かれています。これをバイトでカウントすると、一応、GAWK3.1.5 for Windows 日本語版と変わらない挙動となるのですが、ここでもう一工夫します。
prec によって文字列が削られた場合、文字列の終端が文字化けすることがあります。2バイトで構成される日本語文字の先頭バイトのみ取り出されたときです。この文字化けした断片は length() や substr() で拾うことのできない厄介な存在なので、この対策も同時に行ってしまいましょう。
ラベル pr_tail: 1461以降を下記に変更
1461 : else if (gawk_mb_cur_max > 1 && prec < arg->stlen) {
1462 : if (cs1 == 's') {
1463 : assert(cp == arg->stptr || cp == cpbuf);
1464 : if (!mbc_prec_char_check(arg->stptr, prec)){
1465 : bchunk_broken_mbc(cp, copy_count);
1466 : while (fw > prec) {
1467 : bchunk_one(fill);
1468 : fw--;
1469 : }
1470 : s0 = s1;
1471 : break;
1472 : }
1473 : }
1474 : }
1475 : bchunk(cp, copy_count);
1476 : while (fw > prec) {
1477 : bchunk_one(fill);
1478 : fw--;
1479 : }
1480 : s0 = s1;
1481 : break;
1461 :条件に prec より長い文字列(文字列が削られるとき)を追加
※アサーションから漏れるマルチバイト文字列については後日考えることにする
※本当に必要なのかも執筆時点では不明なので...
1464 :prec に相当する最終文字がマルチバイト文字の断片でないか調べる(後述)
1465 :断片化したマルチバイト文字をスペースに置き換える(後述)
1466-1474 余った部分をスペースで整形し、出来上がった整形文字列を代入
1475以降 原文のまま
mbc_prec_char_check()
1 : static int
2 : mbc_prec_char_check(const char *ptr, size_t numbytes)
3 : {
4 : mbstate_t cur_state;
5 : int mb_len;
6 :
7 : memset(& cur_state, 0, sizeof(cur_state));
8 :
9 : while (numbytes > 0) {
10 : mb_len = mbrlen(ptr, numbytes, &cur_state);
11 : if (mb_len <= 0)
12 : break;
13 : ptr += mb_len;
14 : numbytes -= mb_len;
15 : }
16 : if (mb_len < 0) return 0;
17 : else return 1;
18 : }
この関数の第一引数に対象文字列、第二引数に prec が入ってきます。文字列の先頭から prec バイトの位置にある文字がマルチバイト文字(日本語)の先頭バイト(断片)だった場合ゼロを返します。
記述位置はどこでもよいですが、mbc_char_count() 定義部の下あたりがよろしいかと思います。
関数プロトタイプ宣言を builtin.c の上部(mbc_char_count()宣言部付近)に記述します。
マクロ関数 bchunk_broken_mbc()
1 : #define bchunk_broken_mbc(s, l) if (l) { \
2 : while ((l) > ofre) { \
3 : size_t olen = obufout - obuf; \
4 : erealloc(obuf, char *, osiz * 2, "format_tree"); \
5 : ofre += osiz; \
6 : osiz *= 2; \
7 : obufout = obuf + olen; \
8 : } \
9 : memcpy(obufout, s, (size_t) (l - 1)); \
10 : char *broken_mbc = " "; \
11 : memmove(obufout + l -1, broken_mbc, 1); \
12 : obufout += (l); \
13 : ofre -= (l); \
14 : }
このマクロ関数は format_tree() 最上部に記述のある #define bchunk(s, l) と同じでバッファを用意して文字列をコピーするものですが、相違点は、最後尾の1バイトをスペースにしてしまうところです。
このマクロ関数を 件の bchunk() 定義部の下部に挿入します。
改変箇所はこれで終わりです。改変前と比べて、負荷はあまり変わらないと思います。対象文字列が 日本語混じりで、prec にて削られる時のみ mbchar の計算を行うので、ちょっとだけ軽くなったかもしれません。削られるときは memmove() 1回分負荷が増えています。
あとは MINGW(gcc) を使用してビルドしなおすだけです。
筆者はコマンドプロンプト上 GAWK ソースディレクトリにて
mingw32-make mingw32
とコマンド入力しています。数分で gawk.exe が作成されます。
(注:gawk.exe のファイルサイズが極端に大きくなります およそ 4.7MB !!)
gawk.exe のサイズを小さくする方法
ソースディレクトリ内の Makefile(拡張子なし)を開き、MINGW32設定章の以下の項目(リンクフラグ)を変更します。筆者の環境では「202行目~」
(before) OBJ=popen.o LNK=LMINGW32 LF="-gdwarf-2 -g3" \
( after) OBJ=popen.o LNK=LMINGW32 LF="-gdwarf-2 -g3 -s" \
これで600KB程度になります。
出来上がった gawk.exe を適宜改名して、GAWK4.2.1 バイナリの bin ディレクトリにコピーまたは移動し、改変前と改変後の挙動を確認します。
改変前と改変後の printf() のふるまいの違い
1 : BEGIN {
2 :
3 : book[0] = "プログラミング言語AWK";
4 : book[1] = "AWK Programming Language";
5 : book[2] = "正規表現辞典";
6 : book[3] = "AWKを256倍使うための本";
7 : book[4] = "シェル芸に効く!AWK処方箋";
8 : book[5] = "sed & awkプログラミング";
9 : book[6] = "AWK実践入門";
10 :
11 : print "#printf(\"%20.15s\")にて右詰め fw=20,prec=15";
12 : print "123456789A123456789A";
13 : for (i in book) printf("%20.15s\n", book[i]);
14 : }
結果比較
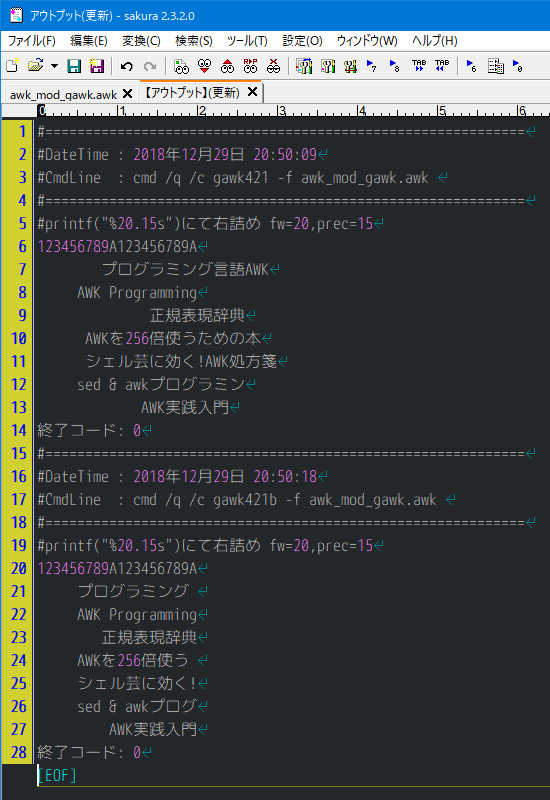
※UTF-8においては、バイトと表示長は同一ではないので、違ったアプローチが必要になります。