GAWK ソースをスペース整形する
これは所謂ビューティファイアの一種です。簡易のレキシカルアナライザを用いて、ソースの自動整形を試みました。ソースの各所にスペースを入れて、可読性を高めるものです。筆者はものぐさな為、ソースにまったくスペースを入れませんので、とても助かります。このソース自体も自動整形されたものです。
Before if(ch~/[ \t]/&&dlm~/_fst/){
After if (ch ~ /[ \t]/ && dlm ~ /_fst/) {
GAWK for win32 4.1.4、4.2.1、5.0.1 にて動作確認しました。
GAWK 3.1.5(日本語版)では動作しません。
以下にサクラエディタ(マクロ)の使用例を掲載します。
マクロ実装の結果
既存awkスクリプトファイルの編集中
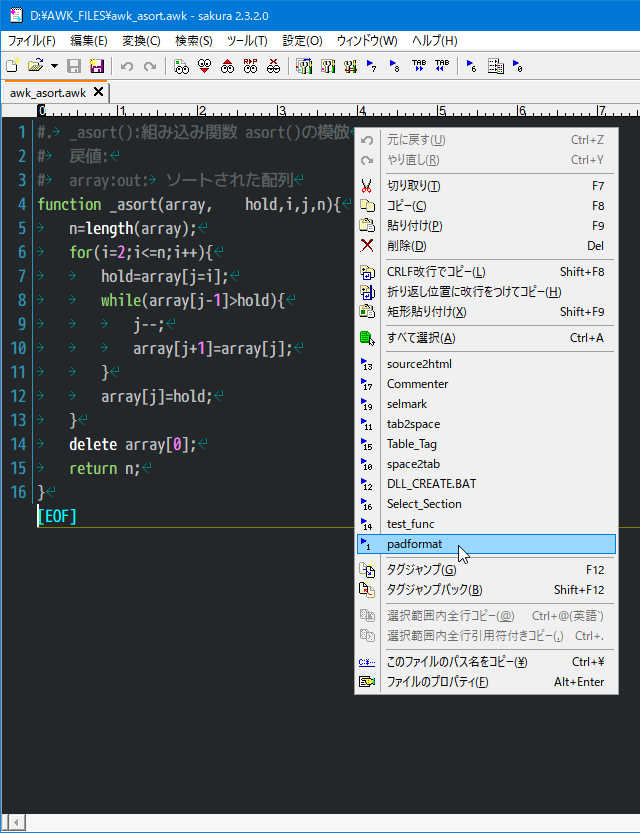
右クリック、コンテキストメニューから「padformat」を選択 MODE 0 動作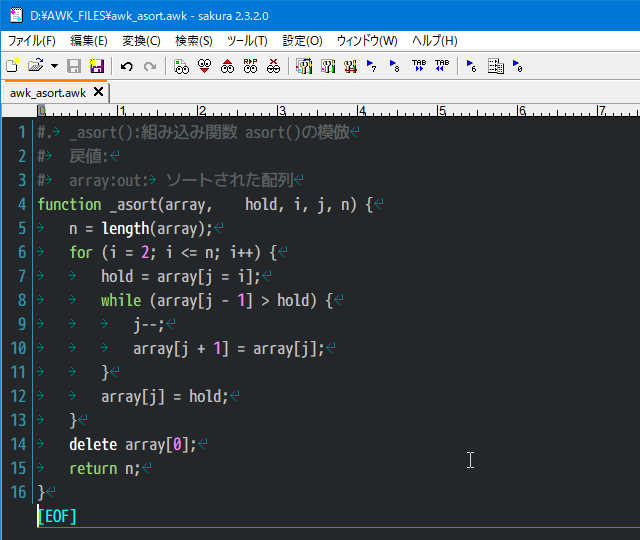
スクリプト全文がスペース(空白)にて整形され、可読性が多少高まる MODE 1 動作
配列のブラケット内は整形しない
右クリック、コンテキストメニューから「padformat」を選択 MODE 0 動作
スクリプト全文がスペース(空白)にて整形され、可読性が多少高まる MODE 1 動作
配列のブラケット内は整形しない
(参考)
GAWK 内臓 pretty print (GAWK 5.0.1 for win32)
ファイル内容確認
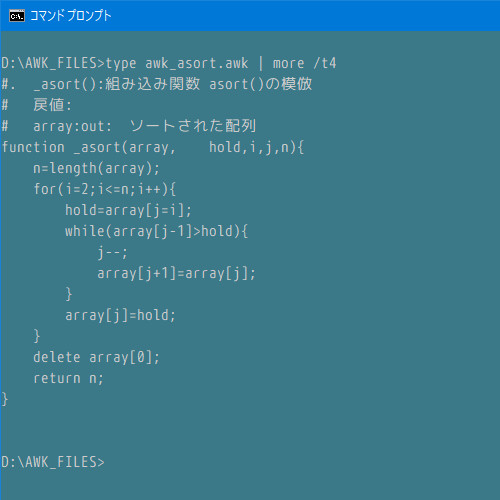
以下のコマンドで pretty print 出力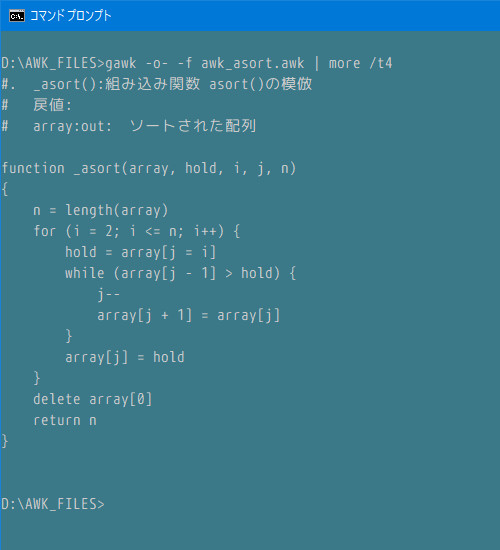
コーディングスタイルが変更され、不要なセミコロンは捨てられる パラメータ内のローカル変数境界(連続スペース)が失われる 関数の上部に改行が加えられる
以下のコマンドで pretty print 出力
コーディングスタイルが変更され、不要なセミコロンは捨てられる パラメータ内のローカル変数境界(連続スペース)が失われる 関数の上部に改行が加えられる
-o の後の - は stdout に出力するという意味で
ファイルに打ち出す場合は -ofoo.awk と書く(空白NG)
コマンドプロンプト上では more でつながない場合、日本語が文字化けする
padformat.vbs サクラエディタ用マクロ
1 : 'サクラマクロ padformat.vbs
2 :
3 : Option Explicit
4 : Dim scmd, spath, sexte, nline, serr
5 :
6 : scmd = "gawk414 -f Y:\padformat\awk_padformat.awk "
7 : With Editor
8 : spath = .GetFilename
9 : sexte = Mid(spath, InStrRev(spath, ".") + 1)
10 : If LCase(sexte) = "awk" Then
11 : .FileSave
12 : scmd = scmd & spath
13 : nline = .ExpandParameter("$y") 'current cursor line num
14 : .SetDrawSwitch 0
15 : .SelectAll 'to overwrite them all
16 : .ExecCommand scmd, 3 'redirect append
17 :
18 : .CancelMode 0
19 : .GoFileEnd
20 : .Up
21 : .SelectLine
22 : serr = .GetSelectedString(0)
23 :
24 : If serr = ("#OK" & vbCrLf) Then 'if padformat returns "#OK"
25 : .Delete
26 : .FileSave
27 : .Jump nline, 1
28 : .CurLineCenter
29 : Else
30 : .Undo 'error
31 : Call MsgBox(serr,vbOKOnly,"padformat")
32 : End If
33 :
34 : .SetDrawSwitch 1
35 : .ReDraw 0
36 : End If
37 : End With
6行目 scmd に awk_padformat.awk のパスを書いて、サクラエディタの macros ディレクトリにコピーしてください。
ファイル内の文字列を全選択して、上書きするだけですので、他のエディタでもマクロを搭載しているものであれば、同じように扱えるのではないかと思います。
awk_padformat.awk
BEGIN
1 : # awk_padformat.awk AWKソースを空白整形する
2 :
3 : #. BEGIN:各辞書の初期化
4 : BEGIN {
5 : _lex_init();
6 : _pad_init();
7 : MODE = 0; #MODE0 配列[]の中も整形する MODE1 整形しない
8 : }ACTION_01
9 : #. ACTION_01:字句解析し、空白整形する
10 : {
11 : lex_awk_s($0, la);
12 : print padformat(la, MODE);
13 : }END
14 :
15 : #. END:最終行に書き込み(マクロで削除)
16 : END {
17 : if (_erct) for (i in _er) print _er[i];
18 : else print "#OK";
19 : }padformat()
20 : #. padformat():適切な位置に空白を挿入する(行単位)
21 : # 戻値: 整形後の1行
22 : # lexa:in: lex_awk_simple()で作られた配列
23 : # mode:in: mode1 配列[]の中を整形しない mode0 する
24 : # 余分な空白を除去しない(付加するのみ)
25 : function padformat(lexa, mode, c, i, tok,\
26 : ptok, ntok, nhead, tstr, brct) {
27 : c = length(lexa);
28 :
29 : while (i <= c) {
30 : tok = lexa[++i];
31 : #注目tokの前後を取得 ※要素数が増加するので注意
32 : ntok = lexa[i + 1]; #注 i=cの時lexa[c+1]=""を作成
33 : ptok = lexa[i - 1]; #注 i=1の時lexa[0]=""を作成
34 : nhead = substr(ntok, 1, 1);
35 :
36 : if (mode && tok ~ /^\[$/) {
37 : tstr = tstr tok;
38 : brct++;
39 : }
40 : else if (mode && tok ~ /^\]$/) {
41 : tstr = tstr tok;
42 : brct--;
43 : }
44 : else if (brct) { #mode1 []の中を整形しない
45 : tstr = tstr tok;
46 : }
47 : else if (tok in _cond) { #if/for/while/[,]の挙動
48 : if (ntok in _cond_s) tstr = tstr tok;
49 : else tstr = tstr tok _sp;
50 : }
51 : else if (tok in _oper) { #演算子の挙動
52 : if (ptok in _oper_s) tstr = tstr tok; #前方
53 : else {
54 : #スペースがダブる可能性 作成中のtstrの末尾を確認
55 : if (substr(tstr, length(tstr)) !~ / /)
56 : tstr = tstr _sp tok;
57 : else tstr = tstr tok;
58 : }
59 : if (!(ntok in _sp_tab)) { #後方
60 : if (tok !~ /^-$/) tstr = tstr _sp;
61 : #単項演算子マイナス
62 : else if (!isunary(lexa, i)) tstr = tstr _sp;
63 : }
64 : }
65 : else if (tok ~ /^)$/) { #[)]の挙動
66 : if (nhead in _a_z) tstr = tstr tok _sp;
67 : else tstr = tstr tok;
68 : }
69 : else if (tok in _semi_s) { #[;}]の挙動
70 : if (i != c && !(ntok in _comt_s)) {
71 : tstr = tstr tok _sp;
72 : } else tstr = tstr tok
73 : }
74 : else if (tok ~ /^:$/) { #[:]の挙動
75 : if (incase(lexa, i)) tstr = tstr tok; #case文か
76 : else { #3項演算子
77 : if (ptok in _sp_tab) tstr = tstr tok; #前方
78 : else tstr = tstr _sp tok;
79 : if (!(ntok in _sp_tab)) tstr = tstr _sp; #後方
80 : }
81 : }
82 : else if (tok ~ /^{$/) { #[{]の挙動
83 : if (i != 1 && !(ptok in _sp_tab)) { #前方
84 : #スペースがダブる可能性 tstrを確認
85 : if (substr(tstr, length(tstr)) !~ / /)
86 : tstr = tstr _sp tok;
87 : else tstr = tstr tok;
88 : } else tstr = tstr tok;
89 : if (i != c && !(ntok in _sp_tab)) tstr = tstr _sp; #後方
90 : }
91 : else if (tok in _ret_ex) { #return exitの挙動
92 : if (i != c && !(ntok in _retx_s)) tstr = tstr tok _sp;
93 : else tstr = tstr tok;
94 : }
95 : else {
96 : tstr = tstr tok;
97 : }
98 : }
99 : return tstr;
100 : }_pad_init()
101 : #. _pad_init():辞書と大域変数
102 : # 戻値:
103 : function _pad_init( oper, cond, unary, ct, ar, i) {
104 : # ! ++ -- : :: を除外した全ての演算子
105 : oper = "+,-,*,/,^,%,=,~,<,>,?,&,|,+=,-=,*=,/=,%=,\
106 : ^=,!~,==,!=,<=,>=,&=,&&,||,>>,<<";
107 : unary = "(.,.[.{.:.return.exit" ;
108 : cond = ",.if.for.do.while.switch.case";
109 :
110 : ct = split(oper, ar, ",");
111 : for (i = 1; i <= ct; i++) {
112 : _oper[ar[i]];
113 : _unary[ar[i]];
114 : }
115 :
116 : ct = split(unary, ar, ".");
117 : for (i = 1; i <= ct; i++) _unary[ar[i]];
118 :
119 : ct = split(cond, ar, ".");
120 : for (i = 1; i <= ct; i++) _cond[ar[i]];
121 :
122 : _cond_s[" "]; _cond_s["\t"]; _cond_s["\\"];
123 : _oper_s[" "]; _oper_s["\t"]; _oper_s["("];
124 : _semi_s[";"]; _semi_s["}"];
125 : _comt_s["#"]; _comt_s[" "]; _comt_s["\t"];
126 : _ret_ex["return"]; _ret_ex["exit"];
127 : _retx_s[" "]; _retx_s["\t"]; _retx_s[";"];
128 : _case_s["case"]; _case_s["default"];
129 : _sp_tab[" "]; _sp_tab["\t"]; #lex兼用
130 :
131 : _sp = " "; #整形に使うスペース
132 : }isunary()
133 : #. isunary():マイナス単項演算子であるか i>0 必須
134 : # 戻値: 1 単項演算子である 0 単項演算子でない
135 : # ar:in: 配列(lex後のtoken配列)
136 : # i:in: 添字(現在カウンタ位置)
137 : function isunary(ar, i) {
138 : #空白でなくなるまで配列の前方に戻る
139 : while (--i) if (!(ar[i] in _sp_tab)) break;
140 : if (!i) return 1; #左辺第一項(?)
141 : else if (ar[i] in _unary) return 1; #演算子と「(,[{:return exit」
142 : else return 0;
143 : }incase()
144 : #. incase():添字i以前にcase/defaultがあるか i>0 必須
145 : # 戻値: 1 case/defaultが前方にある 0 ない
146 : # ar:in: 配列(lex後のtoken配列)
147 : # i:in: 添字(現在カウンタ位置)
148 : function incase(ar, i) {
149 : while (--i) if (ar[i] in _case_s) break;
150 : if (i) return 1;
151 : return 0;
152 : }lex_awk_s()
153 : #. lex_awk_s():簡易レキシカルアナライザ
154 : # 戻値: トークン数(resの要素数)
155 : # str:in: 1行のAWKソース
156 : # res:out: 配列
157 : function lex_awk_s(str, res, len, i, ib, ch, ret,\
158 : once, fcon, prev, pos, ct, tmp) {
159 : i = 1;
160 : prev = "first";
161 : delete res; #配列を初期化
162 : len = length(str);
163 : if (substr(str, len) ~ /\\/) fcon = 1; #行継続確認
164 :
165 : while (i <= len) {
166 : ch = substr(str, i, 1);
167 : ib = i; #切り取り開始位置保存
168 :
169 : if (!once) #正規表現/リテラル 前行よりデリミタ引き継ぎ
170 : if (_cont_ch == "") once = 1;
171 : else { once = 1; ch = _cont_ch; } #デリミタ設定(i=1)
172 :
173 : if (ch in _a_z) ch = "z";
174 :
175 : switch (ch) {
176 : case /z/: #識別子
177 : while (tmp = substr(str, ++i, 1))
178 : if (!(tmp in _a_9)) break;
179 : ret = prev = substr(str, ib, i - ib);
180 : break;
181 : case /[0-9]/: #数値
182 : if (ch ~ /0/ && substr(str, i + 1, 1) ~ /[xX]/) {
183 : i++; #x Hex
184 : while (tmp = substr(str, ++i, 1))
185 : if (!(tmp in _hexd)) break;
186 : }
187 : else {
188 : while (tmp = substr(str, ++i, 1))
189 : if (!(tmp in _frac)) break;
190 : if (tmp !~ /[eE]/) ; #nop Oct/Dec
191 : else { #指数
192 : if (substr(str, ++i, 1) ~ /[\-+]/) i++; # i +1 or +2
193 : for (; i <= len; i++) # i=i init
194 : if (!(substr(str, i, 1) in _nume)) break;
195 : }
196 : }
197 : ret = prev = substr(str, ib, i - ib);
198 : break;
199 : case /"/: #文字列リテラル
200 : pos = litendpos(str, i);
201 : if (pos) { i = ++pos; _cont_ch = ""; } #両端の””含む
202 : else if (fcon) { i = len; _cont_ch = "\""; } #継続
203 : else if (_cont_ch ~ /"/ && str ~ /^"/) { i = 2; _cont_ch = ""; }
204 : else { err(NR, i); i++; _cont_ch = ""; } #エラー
205 : ret = substr(str, ib, i - ib);
206 : prev = ch;
207 : break;
208 : case /\//: #正規表現か除算演算子(直前のデリミタと先行句で判断)
209 : if (prev in _prev) { #正規表現定数
210 : pos = regendpos(str, i);
211 : if (pos) { i = ++pos; _cont_ch = ""; }
212 : else if (fcon) { i = len; _cont_ch = "/"; }
213 : else if (_cont_ch ~ /\// && str ~ /^\//) {
214 : i = 2;
215 : _cont_ch = "";
216 : }
217 : else { err(NR, i); i++; _cont_ch = ""; }
218 : ret = substr(str, ib, i - ib);
219 : prev = ch;
220 : }
221 : else { #除算演算子
222 : tmp = substr(str, ++i, 1);
223 : ret = prev = ch;
224 : if (tmp ~ /=/) { i++; ret = prev = "/="; }
225 : }
226 : break;
227 : case /#/: #コメント
228 : i = len + 1;
229 : ret = substr(str, ib);
230 : break;
231 : default: #演算子 区切り文字等
232 : if (ch in _sp_tab) { #空白
233 : i++;
234 : ret = ch;
235 : }
236 : else { #演算子/句読記号
237 : ret = prev = ch;
238 : tmp = substr(str, i, 2);
239 : i++; #とりあえず1つ進める
240 : if (tmp in _op2) { #2文字演算子?
241 : i++; #もう1つ進める
242 : ret = prev = tmp; #デリミタ書き換え
243 : }
244 : }
245 : break;
246 : }
247 : res[++ct] = ret; #トークン格納
248 : }
249 : return ct - 1;
250 : }_lex_init()
251 : #. _lex_init():辞書とglb変数
252 : # 戻値:
253 : function _lex_init( i, ct, ar, prev, op2, a_z, hex_d) {
254 : prev = "(.,.~.!~.==.!=.first.case.@.=.||.&&";
255 : op2 = "++,--,+=,-=,*=,/=,%=,^=,!~,==,!=,<=,>=,&=,&&,||,<<,>>,::";
256 : a_z = "a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,\
257 : A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,_";
258 : hex_d = "a,b,c,d,e,f,A,B,C,D,E,F";
259 :
260 : #直前字句/正規表現判断
261 : ct = split(prev, ar, ".");
262 : for (i = 1; i <= ct; i++) _prev[ar[i]];
263 : #2文字演算子
264 : ct = split(op2, ar, ",");
265 : for (i = 1; i <= ct; i++) _op2[ar[i]];
266 : #数値
267 : for (i = 0; i <= 9; i++) {
268 : _nume[i];
269 : _frac[i];
270 : _hexd[i];
271 : _a_9[i];
272 : }
273 : _frac["."];
274 :
275 : ct = split(hex_d, ar, ",");
276 : for (i = 1; i <= ct; i++) _hexd[ar[i]];
277 : # lex 識別子 正規表現 /[a-zA-Z_]/ と /[a-zA-Z0-9_]/ の代替
278 : ct = split(a_z, ar, ",");
279 : for (i = 1; i <= ct; i++) {
280 : _a_z[ar[i]];
281 : _a_9[ar[i]];
282 : }
283 : _a_z["$"];
284 :
285 : delete _er; _erct = 0; #エラー用glb変数
286 : _cont_ch = ""; #リテラルか正規表現の持越し用glb変数
287 : }litendpos()
288 : #. litendpos():右ダブルクォートの正確な位置を返す(C/AWK)
289 : # 戻値: 右ダブルクォート位置
290 : # str:in: 文字列
291 : # pos:in: 左ダブルクォート位置
292 : function litendpos(str, pos, rpos, escape, ch) {
293 : rpos = escape = 0;
294 : while (ch = substr(str, ++pos, 1)) { #posの次文字から
295 : if (rpos) break;
296 : switch (ch) {
297 : case /\\/:
298 : (escape) ? escape = 0 : escape = 1; #偽 フラグ設定
299 : break;
300 : case /"/:
301 : (escape) ? escape = 0 : rpos = pos; #偽 終端
302 : break;
303 : default:
304 : (escape) ? escape = 0 : 0; #真 フラグ解除
305 : break;
306 : }
307 : }
308 : return rpos;
309 : }regendpos()
310 : #. regendpos():正規表現末尾の正確な位置を返す(AWK)
311 : # 戻値: 正規表現終端位置(右スラッシュ位置)
312 : # str:in: 文字列
313 : # pos:in: 左スラッシュ位置
314 : function regendpos(str, pos, rpos, escape, bracket, ch) {
315 : rpos = escape = bracket = 0;
316 : while (ch = substr(str, ++pos, 1)) { #posの次文字から
317 : if (rpos) break;
318 : switch (ch) {
319 : case /\\/:
320 : (escape) ? escape = 0 : escape = 1; #偽 Eフラグ設定
321 : break;
322 : case /\[/:
323 : (escape) ? escape = 0 : bracket = 1; #偽 Bフラグ設定 [ 内 ]
324 : break;
325 : case /]/:
326 : (escape) ? escape = 0 : bracket = 0; #偽 Bフラグ解除 [ ]外
327 : break;
328 : case /\//:
329 : (escape || bracket) ? escape = 0 : rpos = pos; #両フラグ 0
330 : break;
331 : default:
332 : (escape) ? escape = 0 : 0; #真 Eフラグ解除
333 : break;
334 : }
335 : }
336 : return rpos;
337 : }err()
338 : #. err():リテラル/正規表現のエラー
339 : # 戻値:
340 : # line:in: エラーが起きた行
341 : # pos:in: エラーが起きた文字位置(タブは1文字)
342 : function err(line, pos) {
343 : _er[++_erct] = "Error line: " line " position: " pos;
344 : }