GAWK 小品集
1ページ割くにはちょっと物足りないけれど、筆者にとって重要なものをここに書いていくことにしました。少しずつ増やしていきます。
床と天井 floor() ceil()
出典:C言語によるアルゴリズム辞典 (mod)
C言語ライブラリにある床と天井です。ある少数「x」について、床の定義は、xを超えない最大の整数で、天井の定義は、xより小さくない最小の整数です。簡潔すぎて逆にわかりにくいですが、整数化に用いる「int()」と何が違うのか、理解する必要があります。
floor_ceil.awk
BEGIN
1 : BEGIN{
2 : x = 89.45;
3 : print "x = " x;
4 : print "int(x) = " int(x);
5 : print "floor(x) = " floor(x);
6 : print "ceil(x) = " ceil(x) "\n";
7 :
8 : x = -5.92;
9 : print "x = " x;
10 : print "int(x) = " int(x);
11 : print "floor(x) = " floor(x);
12 : print "ceil(x) = " ceil(x);
13 : }floor()
14 : function floor(x, x_int){
15 : x_int = int(x);
16 : return (x_int > x)? x_int - 1 : x_int;
17 : }ceil()
18 : function ceil(x, x_int){
19 : x_int = int(x);
20 : return (x_int < x)? x_int + 1 : x_int;
21 : }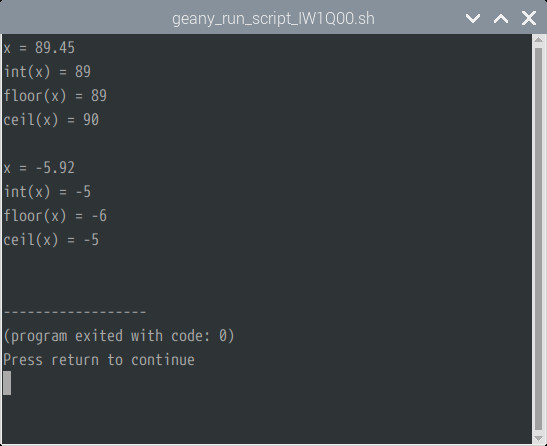
transpose (行/列入れ替え)
出典:sed & awk プログラミング (mod)
awk_transpose.awk
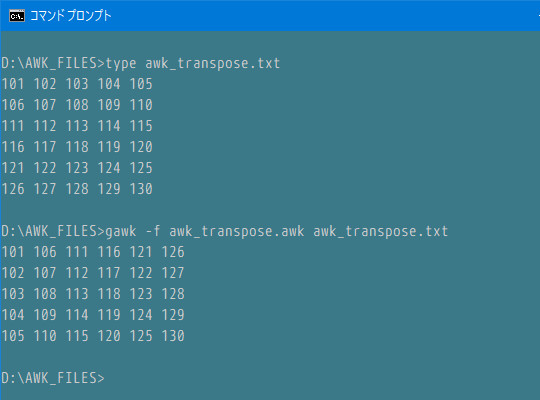
1 : # awk_transpose.awk; 行/列入れ替え
2 : # testfile> awk_transpose.txt
3 : # 出典:sed & awk プログラミング(若干の変更)
4 :
5 : #. ACTION_01:配列への代入(動的に入れ替え)
6 : {
7 : if (NR != 1)
8 : for (i = 1; i <= NF; i++) row[i] = row[i] " " $i;
9 : else
10 : for (i = 1; i <= NF; i++) row[i] = $i;
11 : }
12 : #. END:出力
13 : END {
14 : for (i in row) print row[i];
15 : }
アクション内部で1行目かどうかを延々と分岐するのは不合理なので、以下の通り getline を使用してみました。バッチファイルでコマンド化します。バッチコマンド専用のディレクトリにパスを通し、下記の2ファイルをコピーして使用します。
awk_transpose2.awk
1 : # awk_transpose2.awk; 行/列入れ替え
2 : # testfile> awk_transpose.txt
3 : # 出典:sed & awk プログラミング(変更)
4 : BEGIN {
5 : if (arg1 == "") arg1 = " ";
6 : FS = arg1;
7 : getline; #1行だけ先行して読む(NR=1)
8 : for (i = 1; i <= NF; i++) row[i] = $i; #行列転置1
9 : }
10 : #. ACTION_01:配列への代入(動的に入れ替え)(NR=2~)
11 : {
12 : for (i = 1; i <= NF; i++) row[i] = row[i] FS $i; #行列転置2
13 : }
14 : #. END:出力
15 : END {
16 : for (i in row) print row[i];
17 : }
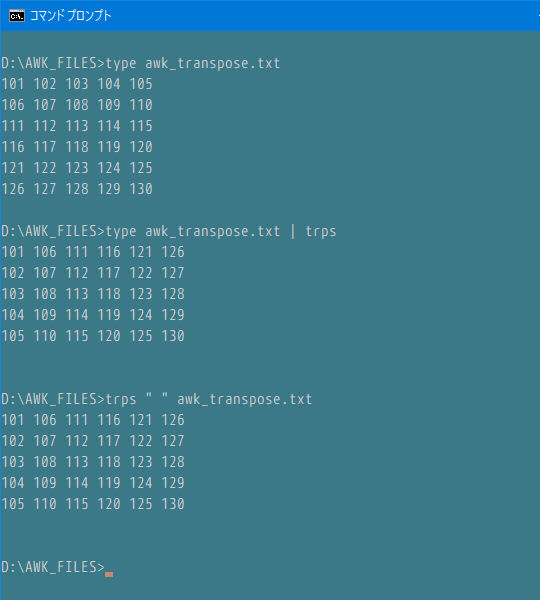
trps.bat
1 : @echo off
2 : rem trps C:\BATCHFILES\
3 : if "%~2"=="" (
4 : rem usage: something command | trps [","]
5 : gawk414 -v arg1=%1 -f %~dp0awk_transpose2.awk | more
6 : ) else (
7 : rem usage: trps "," infile
8 : gawk414 -v arg1=%1 -f %~dp0awk_transpose2.awk %2 | more
9 : )
rev 文字列逆順出力
出典:AWK実践入門 (mod)
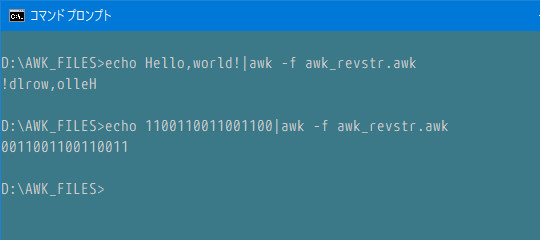
awk_revstr.awk
1 : # awk_revstr.awk;逆順出力
2 :
3 : #. ACTION_01:出力
4 : {
5 : print revstr($0);
6 : }
7 : #. revstr(): 文字列を逆順に出力
8 : # 戻値: 逆順の文字列
9 : # str:in: 入力文字列
10 : function revstr(str, ch, i, ret) {
11 : while (ch = substr(str, ++i, 1)) ret = ch ret;
12 : return ret;
13 : }
splitを使う手法、再帰を使う手法もありますが、処理速度はこれが一番速いです。
文字列の先頭から末尾まで1文字づつ取り出す while (ch = substr(str, ++i, 1)) 筆者がよく用いるコードですが、よそでは全く見かけません。関連書籍やユーザーズガイドにも載っていないので、もしかしたら邪道なのかもしれません。このサイトはこんなのばかりです。 for を用いるコードだと、どうしてもループ終了条件のために(判で押したように) length() が必要になります。それはしかし、冗長ですし、対象が日本語の長文であると無視できないコストになると思うのですが...
while (ch = substr(str, ++i, 1)) { }
蛇足的説明(参考文献がおそらく存在しないので)
AWK のブール(真偽値)判定にて、偽は、0 か "" である ("0"は真)
AWK は C 同様に条件式の中で代入が可能
上記条件式の評価時、substr()に渡される前に i はインクリメントされる
str が空文字の時、条件式は "" となり偽であるから、ループしない
空文字でなければ、先頭から末尾までの条件式は "i番目の文字" となり真であるから、ループする
i が str の末尾を超えると条件式は "" となり偽であるから、ループより脱出
つまり、文字列を与えられると、勝手に文字数分ループする
あらかじめ文字数を調べる必要がないということである
ch は、1ループ毎に先頭からi番目の文字で上書きされる
上述の revstr() のようにループの中で ch を利用して色々する
カウンタ i を初期化すると i の次の文字から取り出しを開始する
break の条件と合わせると、カウンタ i 自体がいい仕事をしたりする
2019/06/12に筆者が2chしながら、3時間考え続けて生み出したアルゴリズムです。単純に length() の分だけ処理速度が微向上します。エレガントでしょう。既出だったらごめんなさい、言ってみたかっただけなんです、エレガント。ちなみに nawk/mawk でも動作します(asciiのみ)ちゃんと。
repeat_str 文字列の繰り返し
出典:awk user's jp (作者不詳)
このスクリプトを小ネタ扱いするのは、非常に恐縮なのですが、カテゴリ的に...
「AWKで文字列の繰り返し」という縛りの中で、最も速い関数だと思います。
繰り返し回数を2進数の桁数と1の部分で考えるなんて、天才としか言いようがないです。
以下原文のまま
1 : # repeat_str(): 文字列 str を num 回連接する
2 : # in: str: 文字列
3 : # in: num: 繰り返し回数
4 : # out: 文字列 str を num 回連接した文字列
5 : function repeat_str(str, num, rep_str, num_bin, arr_bin, memo_rep) {
6 : # 初期化
7 : rep_str = "";
8 : # 以下を分かりやすくするために一旦 2 進数を逆順で記述
9 : num_bin = split(reverse_str(dec2bin(num)), arr_bin, "");
10 : # 2^0 のところは str のまま
11 : memo_rep[0] = str;
12 : # 2^i に対して繰り返しを求める
13 : for (i = 1; i <= num_bin - 1; i++) {
14 : memo_rep[i] = memo_rep[i - 1] memo_rep[i - 1];
15 : }
16 : # 2 進数表記で 1 になっている部分だけを連接させる
17 : for (i = 0; i <= num_bin; i++) {
18 : if (arr_bin[i] == 1) {
19 : rep_str = rep_str memo_rep[i - 1];
20 : }
21 : }
22 : return rep_str;
23 : }
24 : # dec2bin(): 10 進数を 2 進数で返す
25 : # in: num: 10 進数
26 : # out: 2 進数
27 : function dec2bin(num, rem, str) {
28 : while (num > 0) {
29 : rem = int(num % 2);
30 : if (rem == 1) {
31 : str = "1" str;
32 : } else {
33 : str = "0" str;
34 : }
35 : num = int(num / 2);
36 : }
37 : return str;
38 : }
39 : # reverse_str(): 文字列を逆順で返す
40 : # in: str: 文字列
41 : # out: 逆順の文字列
42 : function reverse_str(str, rev_str) {
43 : for (i = length(str); i > 0; i--) {
44 : rev_str = rev_str substr(str, i, 1);
45 : }
46 : return rev_str;
47 : }
結果出力省略
仕組み考察
文字列"@"を26回繰り返す例
まず、26を2進数の文字列 "11010" に変換し、逆順表記 "01011" とします。何故逆順なのか。それは文字列(2進数)に対して、わかりやすく下位の桁(右端)から1文字ずつアクセスするためです。この文字列を分解して配列に詰め込みますが、このインデックスと、後述の参照リスト(メモ配列)のインデックスがリンクします。num_bin には、この2進数の桁数が代入されます。
次に参照リストを作成します。ループを使い、2のn乗倍に str を増殖させていきますが、ループ毎に結果を逐一メモ(都度配列に追加)します。この技術をメモ化と言ったりします。
※この配列は下位第1桁 2の0乗があるゼロベースなので、こちらのインデックスは i-1 とする
増殖の回数は num_bin - 1 回です。
以下の表にまとめてみました。
| arr_bin[i] | 26=0b 11010 | str=str str (2^(i-1)回連接) | memo_rep[i-1] |
|---|---|---|---|
| arr_bin[1] | 0 | @ (初期値) | memo_rep[0] |
| arr_bin[2] | 1 | @@ | memo_rep[1] |
| arr_bin[3] | 0 | @@@@ | memo_rep[2] |
| arr_bin[4] | 1 | @@@@@@@@ | memo_rep[3] |
| arr_bin[5] | 1 | @@@@@@@@@@@@@@@@ | memo_rep[4] |
配列 arr_bin 内のフラグ(1)が「ON」になっている memo_rep[1], memo_rep[3], memo_rep[4]を連結すると、26回の繰り返しとなることが分かります。実質7回の連接を行い、結果を導き出しています。
これが仮に 100万回 の繰り返しですと、
0b 11110100001001000000 (num_bin=20), 7回連接
memo_rep[19] (524,288rep), 19回連接
計26回の連接で結果を生成します。速いはずです。
2進数20桁での最大値は 1,048,575(dec) ですが、この時ですら39回の連接で済みます。
表を見ると、ちょっと違和感を感じる箇所があります。arr_bin のインデックスです。これがゼロベースだとすっきりします(2のべき乗の指数として表現できてmemo_repと揃う)。それと、17行目の for() は、この場合、i=1 で初期化するべきです。このアルゴリズムはとても速いので、チョットいじらせていただいて、MSYS2 のコマンドにしてしまいましょう。コマンド名は reps にします。
.bashrc/MSYS2
function reps(){
if [ $# -lt 2 ]; then
gawk -v arg2="$1" -f ~/awkf/awk_repstr_u8.awk
else
gawk -v arg1="$1" -v arg2="$2" -f ~/awkf/awk_repstr_u8.awk
fi
}
~/awkf/awk_repstr_u8.awk
1 : # awk_repstr_u8.awk: 文字列のリピート
2 : # MSYS2(bash)のコマンドとして組み込む
3 : # usage: reps "something string" numeric
4 : # : somthing command | reps numeric
5 : # 文字列に空白がない場合引用符は不要
6 :
7 : #. BEGIN: 引数を設定
8 : BEGIN {
9 : str = arg1;
10 : num = arg2;
11 : if (num == "" || num < 0 || num != num + 0) num = 1;
12 : else num = int(num);
13 : if(str!= ""){ print repstr(str, num); exit; }
14 : }
15 : {
16 : print repstr($0, num);
17 : }
18 : #. repstr(): 文字列 str を num 回連接する
19 : # 戻値: 文字列 str を num 回連接した文字列
20 : # str:in: 文字列
21 : # num:in: 繰り返し回数
22 : function repstr(str, num, arr_bin, c, memo_rep, i, rep_str) {
23 : do { # numを2進数へ 下位から格納
24 : arr_bin[c++] = num % 2;
25 : num = int(num / 2);
26 : } while (num)
27 : memo_rep[0] = str;
28 : for (i = 1; i < c; i++) # 2進桁数-1回 連結(メモ化)
29 : memo_rep[i] = memo_rep[i - 1] memo_rep[i - 1];
30 : for (i = 0; i < c; i++) # "1"の部分だけ連結
31 : if (arr_bin[i]) rep_str = rep_str memo_rep[i];
32 : return rep_str;
33 : }
特に速くなるわけではありませんが、do-while句で arr_bin を直接初期化します。ゼロベースの配列となり、カウンタ c はそのまま配列の要素数(2進数の桁数)となります。arr_bin とmemo_rep のインデックスが揃いますので、最後の for句は i をゼロで初期化し、その i で2つの配列の値にアクセスします。
上述の例では以下のようになります。
| arr_bin[i] | 26=0b 11010 | str=str str (2^i 回連接) | memo_rep[i] |
|---|---|---|---|
| arr_bin[0] | 0 | @ (初期値) | memo_rep[0] |
| arr_bin[1] | 1 | @@ | memo_rep[1] |
| arr_bin[2] | 0 | @@@@ | memo_rep[2] |
| arr_bin[3] | 1 | @@@@@@@@ | memo_rep[3] |
| arr_bin[4] | 1 | @@@@@@@@@@@@@@@@ | memo_rep[4] |
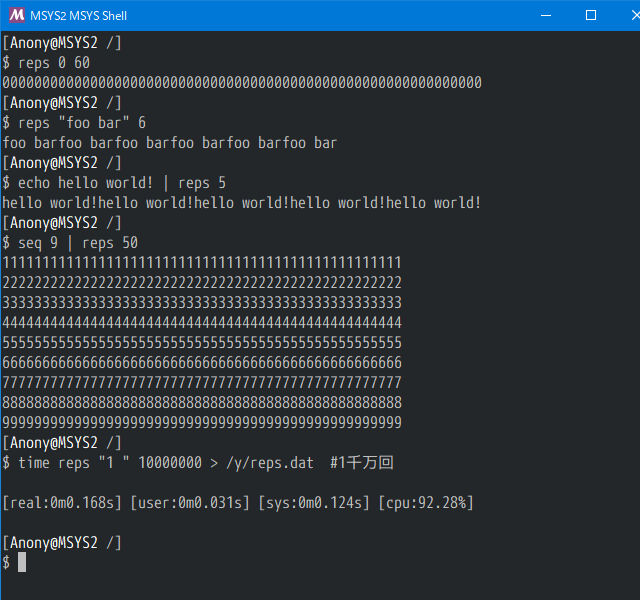
2文字 1千万回の繰り返しが 31ms(user) で生成できてしまいます。アルゴリズムって大切ですね。
愚直に、1千万回 printf(awk) で書き連ねるという力業では、7374ms かかります。その処理速度の差は、およそ 230倍にもなります。printf(bash)では、もっとかかりそうです。
nC2テーブル
出典:筆者作
CAD等にて、平行でない直線(線分ではない)がn本ある場合、nC2個の交点があります。これを算出する際、総当たりのテーブルがあると全体の計算量が約半分に減ります。
awk_nc2.awk
1 : #. BEGIN:nc2()の検証
2 : BEGIN {
3 : #nC2テーブル生成
4 : n = 14;
5 : ret = nc2(a1, a2, n);
6 : printf("nC2:\nn = %d\nret = %d\n", n, ret);
7 :
8 : #nC2テーブルの中身
9 : for (i = 0; i < ret; i++) {
10 : printf("(%d, %d)", a1[i], a2[i]);
11 : if ((i + 1) % 5 == 0) print "";
12 : else printf(" ");
13 : }
14 : }
15 : #. nc2():nC2テーブル(ゼロベース)を生成する
16 : # 戻値: nC2組合せ数
17 : # table1:out: 第一テーブル
18 : # table2:out: 第二テーブル
19 : # n:in: ターゲットの要素数
20 : # 例) n=5 下記のテーブルを生成する
21 : # table1[]⇒{0,0,0,0,1,1,1,2,2,3}
22 : # table2[]⇒{1,2,3,4,2,3,4,3,4,4}
23 : function nc2(table1, table2, n, z,\
24 : i, sct, tct, uct, lct, gct) {
25 : z = n * (n - 1) / 2;
26 : i = 0; #table1,2のインデックス
27 : sct = 0; #table1の値
28 : tct = 1; #table2の値
29 : uct = 0; #lctとタイミングを生成
30 : lct = n - 1; #uctとタイミングを生成
31 : gct = 1; #tctをカウントアップ
32 : while (z - i) {
33 : if (uct == lct) {
34 : lct--;
35 : uct = 0;
36 : sct++;
37 : tct = ++gct;
38 : }
39 : table1[i] = sct;
40 : table2[i] = tct;
41 : uct++;
42 : tct++;
43 : i++;
44 : }
45 : return z;
46 : }
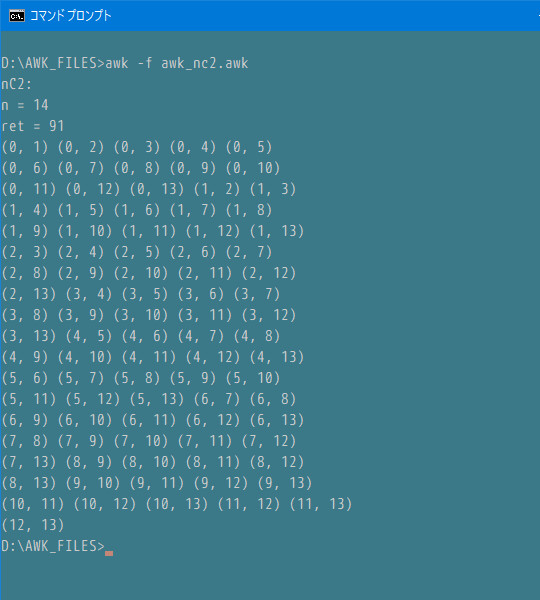
ブルートフォースですので、アルゴリズム的には特に工夫があるわけではありませんし、高速でもありません。配列テーブルを利用しようとしていること、それ自体を見直すべきかもしれません。例えば、関数で nC2(14,20); とすると ar[0]==1,ar[1]==8 を生成するものとか。しかし、参照元がブルートフォースなもの(直線の交点)なので、原理的に一緒か、これよりも遅くなりそうな気もします。
配列テーブルの場合、1000本の直線、組み合わせ499,500通り、所要時間 user:265(msec) ですので、単純に、1万回の関数呼び出しが、5.305(msec)以内にできないと採算が取れない計算になります。全然無理ですね。結局これがベストではないにしろ、ワーストでもないということでしょうか。
rewind 巻き戻し
出典:GAWK User's Guide 10.3.2 Rereading the Current File (mod)
ACTION中に現在ファイルを最初から読み直すことができます。読み直した際のACTIONを別に書いておけば、すごそうなことができそう。
awk_rewind.awk
1 : #. BEGIN:最終行番号と列数
2 : BEGIN {
3 : while (getline < ARGV[1] > 0) {
4 : (max < NF) ? max = NF : 0;
5 : fl++;
6 : }
7 : close(ARGV[1]);
8 : }
9 : #. ACTION_01:列ごとに出力
10 : {
11 : if (!_rewound) print $1;
12 : else print $(_rewound + 1);
13 : if (FNR == fl && _rewound + 1 < max) rewind();
14 : }
15 : #. rewind():ACTION巻き戻し
16 : # 戻値:
17 : # _rewound 巻き戻し回数 glb
18 : function rewind( i) {
19 : for (i = ARGC; i > ARGIND; i--) ARGV[i] = ARGV[i - 1];
20 : ARGC++;
21 : ARGV[ARGIND + 1] = FILENAME;
22 : ++_rewound;
23 : nextfile;
24 : }
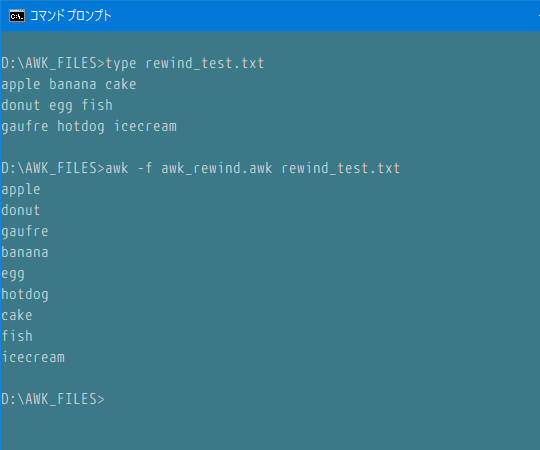
配列を使用せずにこういうことができるようになります。巨大ファイルでレコードを配列に保存できない場合や、同一ファイルを複数回(実行時に決定される)読まなければならない場合に有効です。