GAWK 指定表示長さでデータを改行する
UTF-8/Shift_JIS で記述された改行のないデータ(日本語混在)を、指定長さ「以下」で折り返します。
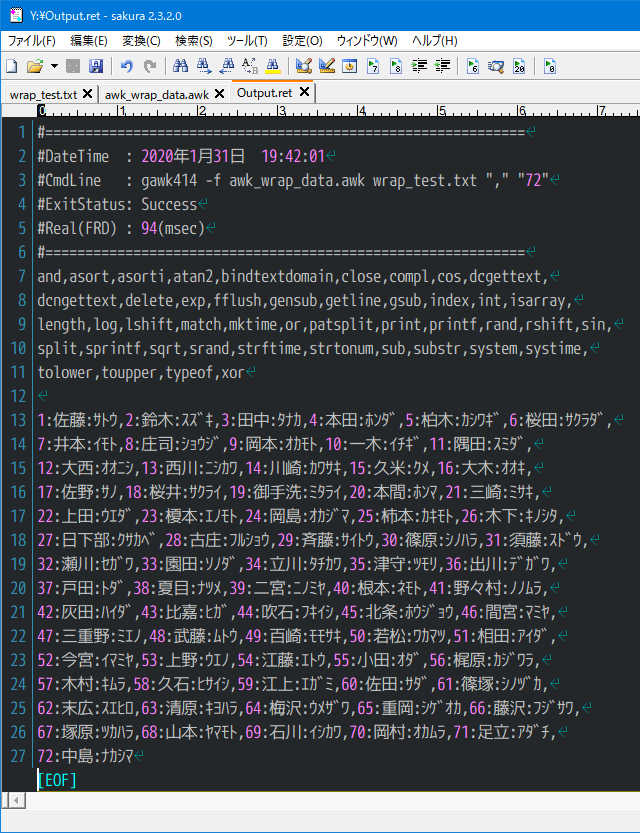
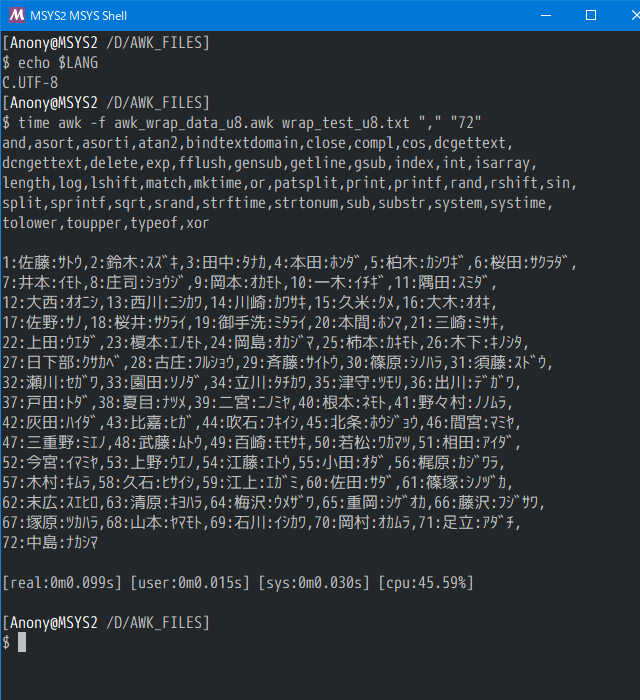
下記の例では区切り文字「","」最大表示長「"72"」を指定して改行付きデータに変換します。
別ページ "GAWK 文字列をバイト単位(表示長さ)で数える" より textf() のデータ版です。
wrap_test.txt (カンマ区切り 折り返しなし)
and,asort,asorti,atan2,bindtextdomain,close,compl,cos,dcgettext,dcngettext,delete,exp,fflush,gensub,getline,gsub,index,int,isarray,length,log,lshift,match,mktime,or,patsplit,print,printf,rand,rshift,sin,split,sprintf,sqrt,srand,strftime,strtonum,sub,substr,system,systime,tolower,toupper,typeof,xor
1:佐藤:サトウ,2:鈴木:スズキ,3:田中:タナカ,4:本田:ホンダ,5:柏木:カシワギ,6:桜田:サクラダ,7:井本:イモト,8:庄司:ショウジ,9:岡本:オカモト,10:一木:イチギ,11:隅田:スミダ,12:大西:オオニシ,13:西川:ニシカワ,14:川崎:カワサキ,15:久米:クメ,16:大木:オオキ,17:佐野:サノ,18:桜井:サクライ,19:御手洗:ミタライ,20:本間:ホンマ,21:三崎:ミサキ,22:上田:ウエダ,23:榎本:エノモト,24:岡島:オカジマ,25:柿本:カキモト,26:木下:キノシタ,27:日下部:クサカベ,28:古庄:フルショウ,29:斉藤:サイトウ,30:篠原:シノハラ,31:須藤:スドウ,32:瀬川:セガワ,33:園田:ソノダ,34:立川:タチカワ,35:津守:ツモリ,36:出川:デガワ,37:戸田:トダ,38:夏目:ナツメ,39:二宮:ニノミヤ,40:根本:ネモト,41:野々村:ノノムラ,42:灰田:ハイダ,43:比嘉:ヒガ,44:吹石:フキイシ,45:北条:ホウジョウ,46:間宮:マミヤ,47:三重野:ミエノ,48:武藤:ムトウ,49:百崎:モモサキ,50:若松:ワカマツ,51:相田:アイダ,52:今宮:イマミヤ,53:上野:ウエノ,54:江藤:エトウ,55:小田:オダ,56:梶原:カジワラ,57:木村:キムラ,58:久石:ヒサイシ,59:江上:エガミ,60:佐田:サダ,61:篠塚:シノヅカ,62:末広:スエヒロ,63:清原:キヨハラ,64:梅沢:ウメザワ,65:重岡:シゲオカ,66:藤沢:フジサワ,67:塚原:ツカハラ,68:山本:ヤマモト,69:石川:イシカワ,70:岡村:オカムラ,71:足立:アダチ,72:中島:ナカシマ
実行結果
 UTF-8/MSYS2/GAWK5.0.1
UTF-8/MSYS2/GAWK5.0.1
awk_wrap_data.awk
BEGINFILE
1 : # awk_wrap_data.awk
2 : # 指定表示長にて日本語混在データの折り返し(区切り文字単位)
3 : # 試験コマンド gawk -f awk_wrap_data.awk wrap_test.txt "," "70"
4 :
5 : #. BEGINFILE: 読めないファイルをスキップ(引数をコマンドプロンプト風に)
6 : BEGINFILE {
7 : if (ERRNO) nextfile;
8 : }BEGIN
9 : #. BEGIN: 各種初期化
10 : BEGIN {
11 : _asc_init();
12 : sep = ARGV[2];
13 : if (!sep) sep = ",";
14 : max_width = ARGV[3];
15 : if (!max_width || max_width < 2) max_width = 80; #最小値2
16 : lim = max_width; #調整 ex) -2(継続文字と改行文字);
17 : }ACTION_01
18 : #. ACTION_01: データ折り返し処理
19 : FILENAME == ARGV[1] {
20 : ct = wrap_data($0, lim, sep, a);
21 : for (i = 1; i < ct; i++) print a[i]; #ex) 継続記号等を付け足す
22 : print a[ct]; #ex) 最終データ
23 : }wrap_data()
24 : #. wrap_data(): データを指定表示長以内で改行(Shift_JIS/UTF-8)
25 : # 戻値: 分割数
26 : # str:in: 入力文字列(日本語データ可)
27 : # col:in: 改行桁
28 : # sep:in: 区切り文字
29 : # ar:out: 出力配列
30 : function wrap_data(str, col, sep, ar, lenb,\
31 : ch, i, si, rp, rem, c) {
32 : delete ar;
33 : si = 1;
34 : while (ch = substr(str, ++i, 1)) {
35 : if (ch in _asc) {
36 : lenb += 1;
37 : if (ch ~ sep) rp = i; #改行候補位置(sep後)
38 : }
39 : else lenb += 2;
40 :
41 : if (lenb < col) ;
42 : else if (lenb == col) { #ch:mbc/!mbc
43 : (si < rp && ch != sep) ? i = rp : 0;
44 : ar[++c] = substr(str, si, i - si + 1);
45 : si = i + 1; rp = lenb = 0;
46 : }
47 : else { #over ch:mbc
48 : if (si < rp) {
49 : i = rp;
50 : ar[++c] = substr(str, si, i - si + 1);
51 : si = i + 1; rp = lenb = 0;
52 : }
53 : else { #指定幅より長いセルで指定幅位置がmbc
54 : ar[++c] = substr(str, si, i - si);
55 : si = i; rp = 0; lenb = 2; #over 次行繰り越し
56 : }
57 : }
58 : } #while終了後 空行 or lenb<colのまま(残文有) or colピッタリ(残文無)
59 : (str) ? rem = substr(str, si) : ar[++c] = "";
60 : if (rem) ar[++c] = rem;
61 : return c;
62 : }_asc_init()
63 : #. _asc_init(): ASCII+半角カナ辞書(Shift_JIS) _asc["ル"]
64 : # 戻値:
65 : function _asc_init( i, hk, ar, qt) {
66 : for (i = 0; i < 128; i++) _asc[sprintf("%c", i)] = i;
67 : hk = "。「」、・ヲァィゥェォャュョッーアイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワン゙゚";
68 : qt = split(hk, ar, "");
69 : for (i = 1; i <= qt; i++) _asc[ar[i]] = 160 + i; #Shift_JIS
70 : _SCLP = " "; #マルチバイト文字の断片を表す文字
71 : }